1. The Colonial Despatches of Vancouver Island and British Columbia
Welcome to the Colonial Despatches project. This document provides detailed guidelines for editors, programmers, maintainers
and research assistants working on the project.
2. Using the Subversion repository
We keep all our XML file and related documents in a Subversion Repository. This is
a version-control system that ensures that every version of every file can be retrieved
if necessary, and prevents one person from inadvertently overwriting changes to a
file made by someone else.
Subversion runs on one of our HCMC servers. In order to use it, you will need to install
a Subversion client on your computer, and also learn a couple of simple command-line
commands. Subversion is usually abbreviated to ‘svn’.
2.1. Installing a Subversion client
How you will do this depends on which operating system you are using.
2.1.1. Windows
Obtain a command-line client from CollabNet (http://www.open.collab.net/downloads/subversion/). Registration is required to download the program, but there is no cost. Make sure
to download the correct version; there are versions for 32-bit and 64-bit Windows.
Once the program is downloaded, install it by double-clicking the downloaded installer
and following its instructions.
2.1.2. Macintosh
Installing svn on Mac has become slightly complicated recently because Apple have
removed it from their XCode toolset. We now have to install it using Homebrew, which
is a package manager for the Mac. Here are the steps:
You should see lots of mysterious information, but the first thing should be the svn
version number which is now installed on your machine.
2.1.3. Linux
Subversion is installed as part of a regular desktop on most Linux distributions.
If you do not have subversion on your Linux:
Open a terminal.
Type: sudo apt-get install subversion
Press return and answer "y" to questions about space.
2.2. Checking out the repository for the first time
Once your subversion client is installed, the first thing we need to do is to check
out the repository. To do this, you need to open a terminal window:
On Windows, click on the Start menu and type cmd into the search box.
On a Mac, select Terminal from the Utilities folder in Applications.
On Linux, press Control + Alt + T.
Now we'll check that svn is installed and working. Type svn checkout and press return. If the terminal responses that there are Not enough arguments provided, then svn is working OK.
Now we'll create a directory for our project files:
(again, just in case anything else has been committed by someone else)
svn commit -m "A message explaining the changes you have made"⚓
*Note: the very first time you commit, SVN might ask for a password. If it does,
hit enter. Then it will ask for your netlink id and then netlink password which you
can give and hit enter.
That's basically it. If you see any warnings or error messages from svn, check that
you're in the right folder in your terminal. You may also see error messages if two
people have been editing the same file at the same time, and Subversion needs you
to make a decision about whose changes should be kept.
For an introduction to XML please see the w3schools tutorial here. The two main components of XML that you should know are “elements” and “attributes”.
4. Working with Oxygen
Your encoding work will all be done in the Oxygen XML Editor. When you install Oxygen, there are lots of applications that come with it: Oxygen Author, Oxygen Developer, Compare Files, Compare Directories and others. But the one you want to work with is always Oxygen XML Editor, which has the blue icon with the red cross on it. Here's how to get started:
Open the Oxygen XML Editor.
Click on Project / Open Project…
Navigate to the coldesp folder in your home directory.
Choose the file coldesp.xpr.
You should see a tree of folders and files down the left of your Oxygen editor. This
includes all the files in the project. You can ignore most of them. The folder that
matters is the trunk/xml folder, where all the TEI files and schemas are kept.
Tip: You will want to enable line wrap for editing purposes:
Open "Options" > "Preferences…"
Select the arrows to open both "Editor" and "Edit Modes"
Then highlight "Text" and in the right side box you can select "line wrap" (see below).
4.1. Validate your files before upload
This is important: always validate any and all XML files in Oxygen before uploading
them to the repository in Terminal/SVN. Get into the habit of saving your files often
(Ctrl + S on your keyboard), and validating often (Ctrl + Shift + V on your keyboard).
To validate the file upon which you are currently working, use the following keyboard
command: Ctrl + Shift + V. Alternatively, click on the validate button in Oxygen's toolbar. The button looks
like this:
To validate multiple files, (1) open Oxygen's built-in file browser, (2) select the
folder you want, and (3) select Validate. Here's a screenshot of the process:
4.2. Oxygen code templates
Our Oxygen project file has a number of useful keyboard shortcuts built into it, which
you can use to speed up your encoding. Generally speaking, to use these, you select
some text in the editor, then press the keystroke shortcut shown in the table below.
The table uses the following key names:
M1
represents the Command key on MacOS X, and the Ctrl key on other platforms.
M2
represents the Shift key.
M3
represents the Option key on MacOS X, and the Alt key on other platforms.
M4
represents the Ctrl key on MacOS X, and is undefined on other platforms.
5. Prepare images for the Colonial Despatches website
5.1. Background
We need to produce three sizes of each image for all of the pages in the online collection:
a thumbnail (60px wide), a medium-sized one (800px wide), and a full-sized image (size
varies). Also the images we receive, usually shot as two-page spreads, get split and
saved as either recto or verso.
Readers can view these images in a couple of ways. The thumbnail images appear to
the right of the digital versions, or transcriptions, of the letter.
On the website, we place the images of the actual letters next to their corresponding
content in the digital transcriptions, so that readers can easily compare our transcriptions
with the originals.
If readers click on the thumbnail image they will be linked to the second way to view
the images, in the “MS images” browser.
The MS (manuscript) images browser has basic features for now, but it allows readers
to jump around in the image collection, and then dive back into the digital transcription
of a given letter. Finally, on the home page of the website, we provide readers with
an index page for all of the manuscript images.
5.1.1. Where we get our images
“Images” refers to photographs of the original letters, which we receive in several forms.
Typically, Chris Petter (now retired), at UVic's McPherson Library, ordered digital
images from places such as Library and Archives Canada (LAC), among other sources.
These images arrive, on a portable hard drive, as digital scans of LAC's archival
reels, or microfilm.
Typically, each frame of the reel captures two pages at once, as they are photographs
of an open book that contains the despatches. We separate, crop, and when necessary,
optimize the images, and then save them as either recto or verso, with an appropriate file name. On occasion, we have used the library’s film scanner
to produce our own scans, which you can read about below.
5.2. Step by step: prepare images for the website
Please read through all of these steps and the FAQ section below before you begin
tackle this process.
After you have read everything in this section, come back and refer to the step-by-step
portion as you proceed. These steps will direct you on how to find appropriate images,
place copies on your desktop, process the images, and create multiple sizes of each
image.
Find a reel of images to process from the Coldesp Image Inventory. To find a reel that requires processing, review the ‘images produced’ column and look for a cell with a value of zero. In the ‘notes’ column write your initials and the date you started processing the images.
On your desktop, create a new folder called ‘RawImages’ and a folder with the name of the collection you are working on. The name of the
collection can be found in the image inventory consisting of the ‘group,’‘series,’ and ‘volume’ information. (See below)
If we were to process the first row (row 2) of the images the folder name would be
co_305_01. NOTE: all lower case and there are NO spaces, use underscores instead and two digits for
the volume number, so ‘01’ NOT ‘1.’
Inside your collection folder create another folder called ‘jpg_full_size.’ This is the folder that you will place your processed images in.
So to recap: you should now have on your desktop a ‘RawImages’ folder and a collections folder named something like ‘co_305_01’ which has a ‘jpg_full_size’ folder inside of it. Now we need to get your raw images…
Raw images are found on the ‘sftp’ server at sftp://nfs.hcmc.uvic.ca/home1t/coldesp/archive. If you don’t have permission to access this directory, please talk to the HCMC staff
or ask the Despatches team to retrieve the needed files for you. You will find the correct reel where your
raw images are located by looking at the ‘reel-folder’ column in the images inventory. Often the collection will start somewhere in the
middle of a reel, if there’s no note about what the file name of the image is that
starts the collection in the image inventory you will have to just scan the contents
of the reel until you find the first page.
Copy the images to your machine by placing them in your ‘RawImages’ folder. NOTE: sometimes a collection is recorded across two reels, if this is the case then please
make copies of the raw images from both reels.
Open Shotwell and select File > Import from folder. Select your ‘RawImages’ folder and ‘import in place.’
Oddly, Shotwell presents images counterintuitively to most image manipulation software. Your first
image will appear at the bottom-right corner (see below). And you will move from right
to left heading up as you work through the images. Not sure why this is, but some
things are better left a mystery.
Typically, you will want to straighten the image, crop, and possibly adjust the saturation
or contrast. You’ll find your image adjustment tools at the bottom of the Shotwell window. Once you’ve completed your adjustments, it’s time to export your image.
You’ll be exporting your image to your ‘jpg_full_size’ folder, in the collections folder. To export your image go to File > Export. Be sure
to give your file the correct name. NOTE: you may see a pop-up that asks you to accept
all current size and quality settings. Click OK to confirm the settings.
For details on cropping please see the FAQ below. For proper file naming see the rename section.
5.3. FAQ on preparing images with Shotwell
5.3.1. What if I want to undo my changes?
Press “Ctrl”+“z” (undo last change) to revert any unwanted changes. This shortcut works for Shotwell, the file-saving dialogue, and most software programs.
5.3.2. How do I know what to trim and what to keep?
As a general rule, we try to keep any features that might be of interest to archivists,
scholars, or other users of the site. For example, in the image below we keep the
tab and the spectral archivist's finger:
However, we always crop away the little slip of paper, called the archival-data slip,
next to the page image. It’s redundant, as our digital records incorporate this information
already.
You will find special cases, where it’s unclear what to trim or keep. As always, consult
the Despatches team if you are uncertain.
5.3.3. How do I know what to rename my files?
Our image filenames derive from the front page of the archival images, which appear
in every collection in some form or another, plus the addition of enough decimal places
to accommodate even the largest image collection within a given repository. Here is
an example of the first page from a collection, with fancy graphics:
As you might guess from the example above, the file name for the next image, the “back” of the page or the verso, would be co_305_01_00001v.jpg. The number then changes with the next recto image (“front”), which would be co_305_01_00002r.jpg, followed by co_305_01_00002v.jpg, and so on.
5.3.4. Is there an efficient way to name the files?
The following answer concerns the “Export…” dialogue in Shotwell. To make this process faster, for all proceeding images, click on one of the existing
renamed images in the “collection” folder. Your new filename will inherit whatever filename you click on. Then, all
you have to do is change the number(s) or letters (the “v” or “r”).
Here are some more details on how this process works:
After clicking ‘Export…’ and navigating to your ‘collection’ folder, you will find the first image named co_305_01_00001r.jpg.
To rename your second image, click on co_305_01_00001r.jpg in the ‘collection’ folder. The ‘filename’ should now become co_305_01_00001r.jpg. Changing the letter ‘r’ to ‘v’ will rename the second image to co_305_01_00001v.jpg.
To rename the third image, you have two options (depending on your preference):
Select the first image name, co_305_01_00001r.jpg, and change the number ‘1’ to ‘2.’ Or…
Select the second image, co_305_01_00001v.jpg, and change ‘1v’ to ‘2r.’
Both options will give you the following result: co_305_01_00002r.jpg.
TIP: In the Shotwell export window make sure you’re viewing your “jpg_full_size” folder as a list and click the “modified” column to make the most recent file show at the top. That way when you are naming
your next file you can click on the top file and either replace the “r” with a “v” or add a new number with an “r.” You’ll be creating hundreds of files, you don’t want to have to scroll to the bottom
to name each file.
5.3.5. What happens to the filenames when I move beyond single digits?
The number of digits in the filenames eventually increases from single digits to double
digits, to triple digits, etc. It’s important that you remember to take away one zero
in the file name each time the number of digits increases as in the examples below:
co_305_01_00001r.jpg
co_305_01_00010r.jpg
co_305_01_00100r.jpg
co_305_01_01000r.jpg
5.3.6. What do I do with duplicates at the ends and beginnings of reels?
Problem: In the raw/archival image files, you encounter a “CONTINUED ON NEXT FILM” image, followed by a “CONTINUED FROM PREVIOUS FILM” image, followed by another archival record sheet, followed by a duplicate image from
the previous reel.
Solution: Incorporate all but the duplicate image, as in the example below:
Note: the order of the recto/verso images can change from collection to collection. For example, the image prior to
the “CONTINUED ON NEXT FILM” image could end on a verso. This would change the “CONTINUED ON NEXT FILM” image to an “r” and the “CONTINUED FROM PREVIOUS FILM” image to an “rx,” and the archival record sheet to a “v.” Easy peasy.
5.3.7. Should I include the “end of volume” slide?
Yes. This should be the last slide in every collection (nearly all collections contain
this page). Straighten, crop, and name it as you would any other file. It doesn’t
matter, either way, if this slide ends up being a recto or a verso.
5.3.8. Any tips for newbies?
Cropping images may seem like a simple and fast process, however it’s very easy to
make mistakes, especially ones that may cost you more time to fix than it did to process
the images in the first place. Here are some tips that may help you avoid making those
mistakes, in no particular order:
Take your time! If you rush, you may skip images, misname them, or process the same
one twice.
Take ‘brain breaks’ as needed, or at least once per hour, as they curb mental fatigue. Check Facebook,
tell a colleague a work-appropriate joke, drink some water, eat a snack, or go outside
and verbally chastise first-year students.
Before you crop an image, jump ahead one image to make sure it has no following duplicate.
Use your keyboard’s arrow keys to navigate through images in Shotwell.
Double-check your work frequently. At first, check every 10 to 20 images to make sure
you (1) are happy with how they are cropped, and (2) that they are named properly.
Compare your images with the raw image files to make sure that your images follow
the correct order. If you screw up, say, image 30 of 300, then every image from 30
onwards will have to be renamed!
5.3.9. Should I make backups of my processed images?
Yes. This step is essential. Backups can be stored in several ways. Ideally, you should
have your files in three locations: (1) on your work computer, (2) stored on the “Coldesp” server (see below), and (3) in another location, such as a datakey, or a non-Coldesp
server, such as your private unix.uvic.ca account, which every UVic student gets by default.
To be able to backup your images on the Coldesp server, ask Martin to create a folder
for you. Have him or another Despatches colleague show you how to access said folder with an FTP client of some kind. At the end of your shift, copy your “RawImages” folder into these backup locations. It goes without saying that the loss of hundreds
of your hard-earned, processed images would, in a word, suck.
5.3.10. How do I handle recto/verso sequence problems?
Problem: In the archival images, you encounter a single-page image that disorders your naming
sequence, whereby the proceeding image would become a recto, when it should be a verso.
Solution: Add an “x” to the end of the name of the single-page document. For example, if the file preceding
the single-page document is named co_305_02_00096r.jpg, the out-of-sequence page becomes
co_305_02_00096rx.jpg, and the following image would resume the sequence as co_305_02_00096v.jpg.
Sometimes, you will find very wonky sequence problems. Always consult your Despatches colleagues for help whenever you are not 100 per cent certain as to how to proceed.
Here’s an example of an archival placeholder that disrupts the recto/verso order:
Note: notice that the page numbers in the original document appear on the top-right corner
of the recto pages (00641r and 00642r).
5.3.11. How do I double-check my work?
Once you’ve processed all the images in a given batch, and they’re all sitting there,
smiling back at you from within the collections folder, you need to make sure that
your collection is perfect. In any image viewer, browse through the whole collection
folder, start to finish, and make sure everything is where it should be.
An easy way to do this is to use the page number stamps, usually located at the top-right
of each recto page, as your guide.
Use these page stamp numbers to count from one to the final image in the collection.
If you skip a number, or see the same number twice, then you have reason to investigate.
5.3.12. I screwed up the order of my images, now what?
Problem: you realize that you made a mistake in your image collection. For example, you accidentally
added the same image, or images, twice. You then delete the copy or copies, and now
your filename order is screwy. Now all the images after the deleted file(s) are one number ahead, and there’s hundreds of them to change…
Solution:KRename to the rescue!
KRename is a filename editor for Ubuntu (Linux). We have used KRename to excellent effect, though the processes involved can be rather complicated, and
should not be attempted without guidance from someone in the know. Please seek technical
support from a Despatches colleague, one who has used KRename before, prior to using this program.
Here are some KRename scripts we have used:
[$1;12]###{13;1}r
[$1;07]###{97;1}r
[$1;5]30_#####{1;1}r
[$1;5]32_#####{466;1}r
[$1;6]_14_#####{185;1}r
[$1;9]#####{10;1}r
If you’re uncomfortable with this process please contact the Despatches team. They’ll be more than happy to help you sort it out.
5.3.13. Am I slower than everyone else at this?
Probably not. We’d rather you go slow and steady than race along and make mistakes.
At first, it might take you four hours to produce 40-50 images. With practise, your
robot genes will kick in, and you’ll soon tickle the team record of over 200 images
in a seven-hour shift.
5.3.14. Adding data to the inventory
Once you’ve processed all your images, please count the number of new images that you created and add that number to the “Images Produced” column in the Coldesp Image Inventory. Also, don’t forget to change your note from [initials, date] “started working” to your new date of completion and add “complete.”
5.4. Create three sizes of the images for the website using image resize script
We create three sizes of the images you prepared by running a short Bash script developed by the Despatches team.
You’ll find the script on the SFTP server at sftp://nfs.hcmc.uvic.ca/home1t/coldesp. You need an FTP client to access this address (pre-installed on the HCMC Linux computers). For your PC you
can use a freeware FTP client such as FileZilla. The script is called ‘image_resize.sh.’ Make a copy and save it to your desktop (ideally beside your collection folder with
a proper name, e.g. ‘co_305_01’).
Make sure the script is executable. There are two ways to do this: a) right-click
on the script, go to Properties > Permissions and toggle on ‘allow executing file as program’; or b) open a terminal window, make sure you are in the desktop (cd Desktop), and
type: ‘chmod u+x image_resize.sh’ (without the quotation marks), then hit enter. See the two examples below:
To run the script use the terminal (once again make sure you are at your desktop).
Type ‘./image_resize.sh’ (no quotations) and hit enter.
You’ll be prompted to confirm the name of your collections folder. Enter the name
of the folder (no typos or the script won’t find the folder) and hit enter.
Ta Dah! The script will have now made two more sets of your images. One size at 60
pixels called thumbnails and another at 800 pixels. These will all be inside your
collections folder.
5.4.1. How to package and deliver your images for upload to the Despatches site
This section assumes that you have FTP access to the “coldesp” server, and that you have a folder on the “coldesp” server, which contains your current work. Martin is the chap who uploads all of the
images to the website proper. FYI: all the images for the site are stored in “coldesp/www/jpg_scans,” which contains three folders, one for each size of image.
By now, you should have three folders on your desktop, one for each size of image.
Ensure that each of your three sizes of web-ready images are in separate folders,
and named as follows: ‘jpg_full_size,’‘jpg_800,’ and ‘jpg_thumbnail.’
Place your three folders into a single folder, which you should name in such a way
that it would make sense to you, or someone else, later. For example, ‘co_6_27_web_ready_images’ tells you everything you need to know. Here’s a picture to help you out with this
whole process:
Upload your folder full of images to your personal folder on the ‘coldesp’ server.
IMPORTANT: Once your pictures are uploaded, set the permissions to allow read/write access to
the ‘group.’ Be sure to set the permissions recursively (to all the files within all the folders).
To set file permissions in Nautilus (Ubuntu’s default file browser), right-click on a folder, then navigate to ‘properties’ > choose the ‘permissions’ tab > and under the heading of ‘group,’ set the ‘folder access’ drop-down selector to ‘create and delete files’; then, under the same heading, set the ‘file access’ drop-down menu to ‘read and write.’ Finally, click on the ‘Apply Permissions to Enclosed Files’ button to commit your changes.
Make backups of your files in your prefered location(s).
Email Martin to notify him that you have new images to upload to the site. As a courtesy,
in your email tell him the ‘filepath’ to the files. For example, ‘coldesp/yourfolder/co_6_27_web_ready_images.’
5.5. Digitize microfilm reels
Rarely, and to complete a given collection or year’s worth of images, we might have
to digitize our own images from a microfilm reel. Chris Petter, the head archivist
at the library (now retired), would order whatever microfilms we might need. The Microform Centre at UVic's McPherson library has a microfilm scanner, the features of which are too
complex to address here, but if you ever have to scan microfilm, follow these general
rules:
Make your scans in greyscale, NOT black and white.
Save your files as as 300 DPI JPEGs, as in ‘image.jpg.’
Name your microfilm scans/images appropriate to their collection of origin. Talk to
your Despatches colleagues about how to do this.
Add your images to the ‘archive’ folder (in the ‘coldesp’ folder), and in the appropriate place. Again, consult your Despatches colleagues about how to do this, and for how to name the folder appropriately.
6. Markup or “tagging” guide
6.1. Introduction
This section provides details on how to markup, or tag, the various content in the XML files. We add to this section each time we
encounter a novel problem, and agree on an appropriate solution. Some issues remain
open, of course.
We also try to keep things in alphabetical order, by heading, to give this otherwise
amorphous mass of words some sort of shape. Most of us use “Ctrl + f” on the keyboard, and then search for the term we want. This method is an easy way
to jump around in this guide
Here’s the code to handle the floating or out-of-line text, using the example word
“that”:
<add place="above">that</add>
Note that the place attribute indicates the location of the inserted word or words
relative to the main line of text. In the above case, the word “that” is inserted “above” the main line of text. You could use other placements as well, such as “bottom,”“margin,”“bottom opposite,” and so on. Here’s an example of each, still using the word “that”:
<add place="bottom">that</add>
<add place="margin">that</add>
<add place="bottom opposite">that</add>
See Martin for guidance on all of this, or for more options for location attributes.
Here’s an example of a “subscript caret” (‸):
Add the following HTML code to the XML document, wherever you want the caret to appear
(you can copy and paste from below):
‸
Add the caret code before or after the word, as it appears in the handwritten document.
In the case of the example image above, where the caret is before the added word “that,” the full code should look like this in your XML document:
Note that the <choice>, <sic>, and <corr> tags are added in the above example. We add these tags so that we can choose to display
the addition-word as either (1) part of the main line of text, our current default,
or (2) as it is in the actual letter, floating away from the main text line.
A superscript caret (^) can be used as per usual in Oxygen.
6.3. Ampersands
XML views ampersands as pure evil! Fine, as code. So, if you have to use an “&” it will appear as invalid. You must use the following text instead wherever an ampersand
appears:
&
Note: ampersands can sometimes appear in longer links. These instances must also be corrected
so that your document is valid and the link isn’t broken.
6.4. <biblScope> and <pb> tags: for page beginnings, or page linking
We need a way to line up the XML files with the images of the pages they represent.
Since the XML document often represents the content of many scanned pages, we need
to show the online reader when a page change occurs in the digital, or online, text.
We start the whole shebang with a <biblScope> tag, as this tag links the digital document to the first page of a given letter.
6.4.1. <biblScope> tags
This tag places the first page of a letter’s image at the beginning of the digital
version. The code for the tag looks like this:
<biblScope type="startPageImage"
facs="folder of images here/individual image here">repeat individual image link here</biblScope>
Here’s a blank code example, which you can copy/paste into your XML document. Make sure you change all the necessary
details so that the image points to the right place!
Here’s what the whole thing looks like in an actual example. Note that the <biblScope> tag appears between the <date> and <series> tags as descendants of the <sourceDesc>.
<sourceDesc><bibl><idno type="repository">CO</idno><idno type="coNumber">305</idno><idno type="coVol">6</idno><idno type="page">46</idno><idno type="coRegistration">6875</idno><idno type="received">received 23 July</idno><idno type="despatchNo">3</idno><date when="1855-05-16">1855</date><biblScope type="startPageImage"
facs="co_305_06_00047r.jpg">co_305_06_00047r.jpg</biblScope><series>V.I.</series><note>Transcribed from microfilm archives, marked up in Waterloo Script, then transformed
into TEI P5 XML.</note></bibl></sourceDesc>
6.4.2. <pb> tags
We use <pb> (page beginning) tags to indicate the beginning of a new page in the document. At
the same time, we use the facs attribute we link to the original image.
On the website, the page beginnings are indicated by the thumbnail images in the right
margin. Users can click on the thumbnails and go to a larger, readable version (the
800px size) and click on the 800px image to see the full-sized version. So, really,
what the following code does is decide where to place the thumbnail image relative
to the digital text.
Below is the code for the <pb> tags. You can use this example as a blank template.
<pb n="co_?_?/co_?_?_00000r.jpg"/>
Here’s an example of an actual <pb> tag in action!
…is ready to receive and consider the Draft of such a Grant as the Company would desire
to receive of lands belonging to the British<pb n="co_305_01/co_305_01_00052v.jpg"/> Crown…
In the above example, we can see that the last word on one page of this despatch was
“British,” then we indicate that the page “breaks” with the <pb> tag, which is followed by the first word on the following page: “Crown.”
We can also see that the content within the <pb> tag breaks down as follows:
<pb n="foldername here/fileneame here"/>
IMPORTANT: page beginning tags always refer to, or introduce, the following page. Also, It is
a “self-closing” tag. There’s no need for a closed, or </pb>, tag.
6.5. <biblScope> and <pb> FAQ
6.5.1. How do I tag catchwords?
Catchwords appear in most correspondences longer than one page, including minutes.
Catchwords indicate a change of page by repeating the final word on the page at the
start of the following one.
Arguably, this system is better for loose sheet collections than page numbers, which
could confuse recipients. Imagine if there were multiple letters in a given packet,
each with its own page three, it could be difficult and slow to repair the order if
they got mixed up. But, catchwords are unique to the content of each correspondence.
So, all you need to do is match the words to match the page order.
Here’s the the XML version of the above example:
… of which Your Grace is far better able to judge, than I to represent; but I may
add that there is much reason to fear that unless her Majesty’s Government <fw type="catchword"
style="text-align: right;">authorise</fw><pb n="co_60_08/co_60_08_00020r.jpg"/> authorise me to take the initiation in this great work, the Country may be found
with
religious teachers supported by the…
And, here’s how the text will appear on the website:
6.5.1.2. What if a catchword occurs right after the end of a paragraph?
Occasionally, a catchword will appear after the final paragraph on a given page, making
the catchword the first word of the beginning of the paragraph on the following page.
In all such instances, place <fw> tags (and the <pb> tag!) between the closing </p> tag and the opening <p> tag of the next paragraph, as in the following example from an actual XML document:
<p> … a toll on goods carried from <name type="place" key="new_westminster">New Westminster</name>.</p><fw type="catchword"
rend="text-align: right;">I</fw><pb n="rg7_g8c_09/rg7_g8c_09_00100v.jpg"/><p>I enclose for your information…</p>
6.5.1.3. What if a catchword doesn’t drop below the line?
This section is for cases where a word is repeated at the beginning of the next page,
but does not drop below the line on the previous page like a normal catchword, as
in the following example:
Treat and tag these just as you would a regular catchword.
6.5.2. How do I know where to place the <pb> tags?
Place the <pb> tags true to where they appear in the image of the despatch. If a page beginnings
halfway through a paragraph, then place it accordingly. Or, if a given paragraph happens
to coincide with a page’s end, then place the <pb> tag after the closed </p> tag. To do otherwise would be to subvert our goal of tagging for content as it actually
appears. Chat with your Despatches colleagues when you are in doubt about where to place the tags.
6.5.3. How do we render page numbers between pages?
These instances are rare, and usually appear in transcriptions of newsprint clippings,
as in the following example:
In the above case, you can see that the number interrupts the text, right in the middle
of a paragraph. In cases like this, we still use an <fw> tag, the same one we use for catchwords. However, we change the type attribute’s value to “pageNum” as in the following example:
<fw type="pageNum"
rend="text-align:center;">7</fw><p>…absolute lords and proprietors of the same…</p>
6.5.4. How do we render letters or other marks between pages?
As with numbers, other marks between pages are also a rare case, as seen in the following
example:
And, as with numbers, these marks require an <fw> tag, the same one we use for catchwords. However, we change the type attribute’s value to “sig” as in the following example:
<fw type="sig" rend="text-align:center;">C</fw>
Note that the rend attribute contains a CSS value of “text-align:center;” in order to make the “C” appear as it does in the letter: centred relative to the paragraph. Also note that
the spelling of “center” in CSS is different than in our guidelines.
6.5.5. How do I add <pb> tags to the minutes?
Always place the <pb> tag to the right of the <div type="minute_entry"> tag, as in this example:
Note: the minutes can sometimes span multiple pages. In this case, add <pb> tags as you would to a despatch, that is, wherever you see a page beginning in the
actual document. This one can sometimes be tricky, as the minutes can jump around
from page to page, or skip pages. If you’re unsure as to how to tag something, consult
your Despatches colleagues.
6.5.6. How do I add <pb> tags to the enclosures?
Always place the <pb> tag to the right of the <div type="enclosure_entry"> tag, as in the following example:
<div type="enclosure_list"><div type="enclosure_entry"><pb n="co_305_02/co_305_02_00038r.jpg"/><ab>Copy, <name key="blanshard">Blanshard</name> to <name key="helmcken_js">John Sebastian Helmcken</name>, <date when="1850-06-22">22 June 1850</date>, appointing…</ab></div></div>
Note: we rarely have transcriptions of the enclosures. Mostly, you use these tags to indicate
the start page of a given enclosure. If we do have a transcribed enclosure, then you
add <pb> tags as you would to a despatch, that is, wherever you see a page beginning in the
actual document.
6.5.7. How do I add <pb> tags to the other files?
Always place the <pb> tag to the right of the <div type="other_entry"> tag, as in the following example:
<div type="other_files"><div type="other_entry"><pb n="co_305_02/co_305_02_00055r.jpg"/><ab>Draft reply, <name key="grey_hg">Grey</name> to <name key="blanshard">Blanshard</name>, No. 7, <date when="1851-04-03">3 April 1851</date>.
<!-- .cm on top both 2726 &amp; 2727 noted - this is answer to both. --></ab></div></div>
Note: we rarely have transcriptions of the “other files.” As with the enclosures, these tags indicate the start page of a given “other file.” If an “other file” is transcribed, then you add <pb> tags as you would to a despatch, that is, wherever you see a page beginning in the
actual document.
6.5.8. What if the pages are out of order?
We handle this one on a case-by-case basis. But, as a general rule, we order everything
as it appears in the image collection. To do otherwise—that is, impose an arbitrary
order—introduces the risk of human error. Also, if we do need to order things differently
in the future, it will be easier to do so starting from a consistent base order.
The archival images are far from from perfect. Occasionally, for example, minutes
are cut off, or could appear several pages later, after an entirely new letter, or
even as a set of enclosures. Enclosures could also appear before or behind the despatch
to which they are associated. Web-based documents, like our Despatches site, are vital to stitching these different threads together.
So, a bend to the general rule is required in cases where documents have migrated
out of order. For example, if a given letter's minutes are half-way through then jump
ahead ten pages, so be it. You will, on the website, see this discrepancy reflected
in your <pb> tags. Each case of disorder is unique and requires attention to detail. If you find
documents out of order, or are confused as to how to proceed, discuss each case with
your Despatches colleagues.
6.5.9. What if there are miscellaneous documents toward the end of the reel?
From time to time, a given collection of images will have miscellaneous files added
toward the end, just before the “index” page but after all the despatches.
Jim and his team indexed these “random” files as “other files,” and placed a list of them at the end of the final file in a given collection. To
indicate that this was done, you will usually find an editorial note, such as the
following example from file B63078.scx: [The following is a collection of miscellaneous
document inserted at the conclusion of the despatches for 1863:]
If you do not find a note as above, then please add one! See the example below for
what this would look like in XML form.
As to what to do, just add your <pb> tags as you would for any other file. Ensure that the order of the list of “other entries” reflects the order of the images, as in the following example:
<div type="other_files"><ab><lb/><lb/> [The following is a collection of miscellaneous documents inserted at the conclusion
of the despatches for <date when="1863">1863</date>:] <lb/><lb/></ab><div type="other_entry"><pb n="co_60_16/co_60_16_00370.jpg"/><ab>John Lindley to Newcastle, <date when="1863-03-18">18 March 1863</date>, forwarding a copy of a letter concerning British Columbia. [Taken in entirety in
correspondence.]</ab></div><div type="other_entry"><pb n="co_60_16/co_60_16_00371.jpg"/><ab>Extract enclosed with Lindley letter above, no salutation or signature, <date when="1863-01-11">11 January 1863</date>, supporting the existing government in British Columbia as just and effective and
discussing at length various aspects of the colonial situation. [Taken in entirety
in correspondence.]</ab></div></div>
6.6. Asterisks, daggers, and more!
This section covers marks intended to link bits of text. These can take a surprising
diversity of forms!
6.6.1. Asterisks
These come in all kinds of shapes and sizes. A basic asterisk (*) can be added to
your XML document with the keyboard [shift + 8]. We use the basic asterisk to indicate
all asterisks in the despatches.
6.6.2. Daggers
Daggers function, essentially, as asterisks do: to indicate a footnote. Daggers point to
a second footnote, when an asterisk is already used.
Here’s an image of a dagger, from the collection. The dagger rests above the “3”:
Here’s an image of the footnote to which the dagger refers:
If you need to represent the dagger in your XML document, then copy/paste the following
symbol as needed: †
6.6.3. Dotted cross
Here's a rare one, usually used to indicate the continuance of text across a page
fold:
If you need to represent the dotted cross in your XML document, then copy/paste the
following as needed: ⁜
6.7. CSS in Your XML document
Thanks to Martin, we now use CSS to define layout elements within the despatches—this applies to such things as centring
text, italics, tables, and the like. CSS allows for far greater freedom and fine-tuning.
6.7.1. CSS: general application
We place CSS elements inside style tags, as in the following example:
Things are set up in such a way that, via the XSLT transformation, rend tags containing CSS will be displayed appropriately on the HTML
pages, i.e., the Despatches website.
6.7.2. CSS: block quotations
See the Blockquotes section for CMOS’s rules for block quotes. Arguably, our method is a bit of a cheat in that we should
be handling blockquotes with a blockquote tag. However, the CSS approach gives us
more flexibility. The following style looks good, so we’ll stick with it for now.
Also, please note that we place the blockquote text within a <p> tag.
<p><hi style="padding-left:20px; display:block;">blockquote text will appear here</hi></p>
6.7.3. CSS: bold text
<hi style="font-weight: bold;">bold text will appear here</hi>
6.7.4. CSS: centre text
<hi style="text-align:center;">1301 N. America</hi>
Note that within the tag the american spelling for “center” is used.
6.7.7. CSS: multiple rules in one tag (a rulesheet)
Perhaps you wish to, as in the example above, centre your text, but also affect other
changes, such as italics. As in the example below, add the desired elements, separated
by semicolons:
When you find a date within a document, first check where it occurs in the code. If
it occurs within an <idno> tag, do not tag it! An instance of a date could include the year, month, and day
(5 March 1847), the year and the month (April 1859), or just the year (1862).
A tagged date must contain at least a year, or the schema will list it as an error. If you find a day or month without a year,
you must use your research skills to deduce the year, or ask a Despatches colleague for help.
The whole date may include a phrase such as the “16th of September, in 1862;” however, the whole date does not include noun phrases such as “The Preemption Amendment Act 1861.”
Generally, dates will appear formatted as “5 March 1847,”“9th November last,” or “19/4/62.” When tagged, the format of the date within the code always remains the same: year-month-day.
When writing bios, please always use the format “5 March 1847,” note that “th” is not used after the “5.” Here are some examples:
<date when="1847-03-05">5 March 1847</date>
<date when="1846-11-09">9<hi style="vertical-align: super; font-size: 80%;">th</hi> November last</date><!-- Note: the date tag wraps around the word “last.” The “last” is part of the content
related to the date. -->
<date when="1862-04-19">19/4/62</date>
Finally, if you make a mistake in your date attribute value, the stuff between the
quotes, the schema will mark it as an error. For example, if you enter <date when="1862-06-31">1862-06-31</date>, a validation error will result because June does not have 31 days, at least in this
universe.
6.8.1. Examples of confusing date tags, and how we deal with them
<date when="1861-06-02">2<hi style="vertical-align: super; font-size: 80%;">nd</hi> June last</date>
<date when="1861-10-15">15th</date> and
<date when="1861-10-21">21st of October last</date>
the <date when="1859-03-10">tenth Instant</date>
the <date when="1859-02-15">15<hi style="vertical-align: super; font-size: 80%;">th</hi></date>
As a general rule, we tag words only specifically associated with a given date. For
example, this means that we usually do not tag the “the” in “the 15th Ultimo.” We base this on the TEI’s following example:
Given on the <date when="1977-06-12">Twelfth Day</date>
However, we may need to tag the “the” in some rare cases for the sake of clarity. Consult your Despatches colleagues as needed.
6.8.2. cert or certainty attribute
We use this attribute rarely. In simple terms, use this attribute in a date when you
are not certain of its accuracy. The cert attribute allows for for values: “high,”“low,”“medium,” and “unknown.”
Dates that lack a year or a month often pose a challenge, and can sometimes remain
uncertain. Consult with your Despatches colleagues. Only after these measures should you add a cert attribute.
Date ranges commonly turn up within the despatches: they use a modified <date> tag. Instead of when, they use from and to. When tagging a date range, select the whole date range phrase, as in the following
example:
Should … your drafts on the amount which will be voted by Parliament for the service
of the Colony for the year <date from="1862" to="1863">1862-63</date>.
6.8.4. Non-consecutive ranges
Some ranges will have an “and” between dates, as in “the 9th and 16th of July.” We treat these as two separate dates and use the when attribute, as in the following example:
<date when="1862-07-09">9th</date> and <date when="1862-07-16">16th of July</date>.
6.8.5. Ultimo [month before] and instant [present month]
Ultimo and instant are Latin terms. Often, you will find them in their abbreviated forms, such as “Ult.” and “Inst.”
Ultimo refers to the month before, and instant refers to the present month. These ones can
be tricky to tag at times. When in doubt, consult your Despatches comrades. Here’s a couple of examples from the files:
Since we had last the pleasure of addressing you on the <date when="1846-08-11">11<hi style="vertical-align: super; font-size: 80%;">th</hi> Ult<hi style="vertical-align: super; font-size: 80%;">o</hi></date> this Settlement
In reply to your letter of the <date when="1849-09-22">22<hi style="vertical-align: super; font-size: 80%;">d</hi> Instant</date>;
Note that the words Instant and Ultimo are included inside the date tags. This is because they refer to the month, and it
would be redundant to have the month outside the date tag. (Example: October 3, 1850
Ultimo = redundant.)
NOTE: If there’s a period after an abbreviated Inst. or Ult., that period is included inside the date tags. The only exception to this rule is
if the period also indicates the end of the sentence.
<date when="1858-01-06">6<hi style="vertical-align: super; font-size: 80%;">th</hi> Inst</date>. Your statement that…
6.8.6. notBefore and notAfter tags
You can use these attributes in cases where the information present is too sparse
to make even a vague conclusion about a given date. For example, an author may write
that an event in question occurred in sometime in “either 1853 or 1854,” in this case, you could add the following attributes:
either <date notBefore="1853" notAfter="1854">1853 or 1854</date>
The above example is one among many variations. Consult with your Despatches colleagues if you are unsure as to how to handle a given date.
6.8.7. Dates in the minutes and sad little numbers all alone
Minutes occur at the end of the primary correspondence and are often added by other
authors. Minutes present a challenge to tagging dates because they are easily missed.
Authors sometimes used a non-standard abbreviation or just a single number. For example,
“26 Jany” or “27” refer to the 26th and 27th of January. To establish the year, you must deduce it
from the chronological sequence started at the opening of the letter. Always look
at the end of the document for minutes. Dates often hide in the minutes and are extremely
hard to find once missed.
Here’s an example from an actual letter, which illustrates that lonely numbers at
the ends of minutes are actually dates:
For example, the author might write that a thing is to be done “on the 15th day of every February.” So, we do not have a specific year! In this case, we use a hyphen to indicate the
missing date information, as in the following example:
…and are recommmenced about <date from="--02-15" to="--02-28">the middle or end of February…</date>
In the above case, the date happens to need from and to. Here’s a short list of examples from the TEI guidelines on the subject:
<date when="--09-11">9/11</date>
<date when="--09">September</date>
<date when="---11">Eleventh of the month</date>
6.8.9. Separating dates from signatures in a <closer> tag
This section assumes that you are familiar with how to tag dates and people. Often,
despatch authors sign/initial and date on separate lines. In cases where they do not,
we display them online as if they had for the sake of readability and consistency.
For example, in the following image, Blackwood has initialed and dated on the same
line:
On the website, it should look like this:
ABd
7/2/48.
Please note that when a <date> tag appears outside a <closer> tag, say inside a <p> tag, the <date> tag will not force a carriage return.
6.8.10. Dates inside <ref type=”co_ref”> tags: DO NOT TAG!
It’s redundant to tag dates within the <ref type="co_ref"> tags. Do not tag these dates. This tag generally appears after the open <opener> tag, as in the following example:
<opener><ref type="co_ref">9801, CO 60/11, p. 18; received 2 November</ref></opener>
So, in the above example, you would ignore “2 November.”
6.9. Task checklist for XML transcription
This list can and should be used as a task checklist for each XML transcription. Hopefully, by working through this list, you will have
completed all that is required to markup and edit a given correspondence. The list
will grow and change as needed.
Insert your three initials and a date [yyyy-mm-dd] within a comment, and place the
comment just before the <teiHeader> tag, as in the following example:
<!-- KSS edit, 2013-09-16-->
Add abstract placeholder after the closed </publicationStmt> tag:
Delete the superfluous head tag and contents that appear between the <div type> and <opener> tags, as in the following example, in which everything in the <head> tag should be deleted (including the tag):
<div type="public_offices"><head>Ward to Hawes (Parliamentary Under-Secretary)</head></div>
Note: we remove this tag and its contents as the information in question appears already
in the teiHeader.
Add some format the document to (1) demarcate content sections, and (2) make it easier
to read long, complex files. You can add the following comments where required; you
would be surprised at what a difference this makes:
Add a couple of carriage returns between the sections you added (see #4, above), and
add a carriage return between paragraphs if this makes things easier to read. As long
as space out paragraphs and other sections to make the XML as readable as possible.
Remove double space bar spaces between sentences, using find/replace.
Compare your xml file's transcription to the scan of the original letter; make the
required changes.
6.9.1. Indigenous Peoples <ip> tags
Mentions of Indigenous Peoples range in the despatches from pointed and detailed to
vague and confusing. Starting in 1852, we’ve begun to tag all mentions of Indigenous
Peoples with the following tag:
In the way that we have created biography and placename entries, we hope to one day
provide a rich database for Indigenous Peoples, by tagging all instances of Indigenous
Peoples’ presence in a similar manner.
Adding Context: Often, Colonial Officials were very vague when referencing the activities of First
Nations groups. For example, they will simply say “Indians” or “the Northern Tribes.” If this is the case please add some context within the <name> tag. For example:
<name type="ip" subtype="group">Indians will freely give information to trading vessels</name>
and NOT
<name type="ip">Indians</name>
We make use of subtype to differentiate between an Indigenous individual and an Indigenous group.
This section discusses how to handle words that are broken, with a hyphen or similar
punctuation, where the remainder of the broken word carries on to the line below,
or to the next page. As in the following example:
As you can see, the word in question is “proposal.” We want to markup the hyphen and the line break, but not render it online, in other
words, we will “regularize” it in the online version.
To do this we need to use a <choice> tag so that if we choose to later, we can display the original, or the content in
the <orig> tag. For now, though, our “choice” is to show the regularized version, or, the content in the <reg> tag. Please refer to the following example, taken from the image above:
On Her Majesty's behalf, to my <choice><orig>propo-<lb/>sal</orig><reg>proposal</reg></choice> that certain lands in Vancouver's…
When we choose to display the above online in the regularized format, it will look
like this:
On Her Majesty's behalf, to my proposal that certain lands in Vancouver's…
But, if we choose to show the original format, it will look like this:
On Her Majesty's behalf, to my propo-
sal that certain lands in Vancouver's…
One of the beauties about the orig/reg display option is that we can configure things
so that the reader can toggle between each view.
Note that there’s no content between in the <reg> tags. This is not necessarily going to be the case in every instance. If you are
unsure as to how to handle a tricky line break word, space, hyphen, or similar symbol,
notify your colleagues.
6.9.4. Links: external (to pages outside the Despatches site)
This format is used to link to a webpage that is outside of the Despatches website, such as a bibliographic entry.
6.9.5. Links: internal (to other Despatches documents)
This format is used to link to another despatch, or page on the Despatches website.
<ref target="cdc:V465HB03">linked content</ref>
NOTE: When you add internal links with the text of "this despatch"—as in
According to <ref target="cdc:V465HB03">this despatch</ref>
—make sure that the correspondence in question is, in fact, a despatch, and not another
type of correspondence. When in doubt, view the letter in question on the website,
which shows you the type of correspondence it is, as in the following example:
6.9.6. Marginalia
Marginalia appears in many of the letters. It is as diverse in location as it is in
content. As far as coding it goes, in simple terms, we organize all the marginalia
in one place (the end of the XML file), then we place a unique link (a <ref> tag) in the code to reflect where it would show up in the actual letter, or as close
as we can get.
In the XML document, all the marginalia content should appear collected together after
all the other sections of content, but before the closing <body> tag (at the end).
Here’s an example of a complete marginalia entry:
<!-- marginalia ==================================== --><div type="marginalia"><div type="marginalis" xml:id="marg1"><ab>Note to Sir John Pelly 21 Septr</ab></div></div><!-- marginalia ends =============================== -->
Once you’ve entered the marginalia as above, you need to indicate its placement within
the body of text. To do this, place the following code as close as possible to where
the marginalia occurs in the letter:
<ref target="#marg1"/>
NOTE: You can add as many marginal notes (“marginalis”) as you like by adding the same number to both the marginalia entry and the “#marg” referent. For example, “marg2” in the marginalia entry appears where “#marg2” is placed the body text, “marg3” appears where “#marg3” is placed, and so on.
Here’s an example of what this looks like:
<!-- marginalia ==================================== --><div type="marginalia"><div type="marginalis" xml:id="marg1"><ab>Note to Sir John Pelly 21 Septr</ab></div><div type="marginalis" xml:id="marg2"><ab>I thought he wanted elf-shaped cookies for lunch?</ab></div><div type="marginalis" xml:id="marg3"><ab>He said that he would darn my socks. So far, I still have holes.</ab></div></div><!-- marginalia ends =============================== -->
So, this means that somewhere in the body of the letter we should find these three
tags:
FYI only: Here’s an example of a rather complex chunk of marginalia, in which a <note> tag has been added within the <marginalis> tag:
<!-- marginalia =============================== --><div type="marginalia"><div type="marginalis" xml:id="marg1"><ab><note xml:id="V52101_1">This text is located in the left margin and runs perpendicular to the main body text.
See image scan.</note> Copy <unclear>to […]/[…]</unclear><lb/><unclear>[…]</unclear> with <name key="pelly">Pelly</name><hi style="text-decoration: underline;">3779</hi><lb/> Copy to Foreign Office<lb/> —<unclear>w<hi style="verticla-align: super; font-size: 80%; text-decoration: underline;">th</hi>[…]</unclear> Hudsons Bay Compy } 18 May / 52<lb/> Ansd 27 Sept / 52 — 5.<lb/><unclear>[…]</unclear> with <unclear>[…]</unclear><hi style="text-decoration: underline;">3778</hi></ab></div></div><!-- marginalia ends ============================= -->
6.9.7. Misplaced addressee information
From time to time, the author of a given despatch places the addressee information
at the bottom of the first page of the despatch. In these cases, we place it at the
end of the digital despatch, but make a note (at the end of the addressee paragraph)
as to where it appears in the original despatch.
Example as follows:
<closer><name type="addressee">To the Right Hon<hi style="superscript">le</hi><lb/> The <name key="grey_hg">Earl Grey</name><lb/> &c &c &c.</name><note>This addressee information appears at the foot of the first page of the despatch.</note></closer>
6.9.8. Missing documents
From time to time, despatches go missing, or are placed elsewhere in the colonial
volumes. Most cases of absent files require a unique approach. The following represents
the quirks we have encountered thus far, and how we handled them.
6.9.8.1. Missing despatch
“Missing despatch” refers to instances where it’s clear, either from Jim's notes (which is often the
case) or from the content, that a despatch is intended or supposed to be present as
part of the collection.
If the despatch is missing we still need to place an opening page image in the header (in the <biblScope type="startPageImage"> tag). Please default to the first transcribed page. For example, if the despatch is gone, but the transcription begins with the minutes,
then place the first page of the minutes in the <biblScope type="startPageImage"> tag.
Notation is required in order to tell the online reader that the despatch is missing.
We indicate this in two ways.
Indicate in [square brackets] the item thought missing from the volume, and be sure to wrap your statement in a <supplied> tag, as in the example below.
Provide notation to indicate to the reader that the document is missing, again, as in the example below.
<supplied reason="missing">[Despatch from Blanshard to Grey.]<note xml:id="V49000A_1">This document is missing from the Colonial Office volume.</note></supplied>
FYI: For full examples see the following XML files: V49000A & V485HB07.
6.9.8.2. No despatch (enclosures only)
“No despatch” refers to instances where it’s clear that no letter or correspondence is associated
with a given set of documents. For example, at the end of some of the volumes there
might be a collection bundled together under a heading, such as “Parliamentary Papers,” or “Treasury,” and so on. Usually, we treat these bundles as we would enclosures, and, more often
than not, Jim of his team have provided a descriptive paragraph for each.
In cases where we have only enclosures, we still need to place an opening page image in the header (in the <biblScope type="startPageImage"> tag). Please default to the first page in the enclosures.
Notation is required in order to tell the online reader that only enclosures appear
in this file. We do so by providing notation to indicate to the reader that only enclosures are present, as in the example below:
[This file contains only enclosures, which appear in a collection entitled “Parliamentary Papers.” They are presented here in the order in which they appear in the Colonial volume.]
FYI: For full examples see the following XML file: V495PA04.
6.9.8.3. Missing image scan
This section refers to instances where you have a transcription, but can’t find an
associated image scan with which to proof it. Possibly, Jim and his team had transcribed
it from elsewhere. Or, as is likely the case, we haven’t received or uploaded the
images associated with the file in question. This is usually due to the images for
a given year appearing in an alternative collection, such as the National Archives
Canada (NAC).
In these cases you are advised to take the following approach:
Clean up the XML as best you can.
Markup, as usual, the place, people, and vessel names, where present.
Write the abstract, but leave the following comment after the opening <noteStmt> tag: ‘The following despatch has not yet been vetted against its corresponding image scan,
which was not available at the time of this writing, [yyyy-mm-dd].’
Here’s a (shortened) example from the collection:
<!-- abstract begins ======================== --><notesStmt><!-- ksw note: the following despatch has not yet been vetted against its corresponding
image scan, which was not available at the time of this writing, 2009-12-18. --><note><name key="grey_hg">Grey</name> writes <name key="blanshard">Blanshard</name> to […].</note></notesStmt><!-- abstract ends ========================= -->
6.9.9. Multiple page image collections for one XML file
This section presumes that you have a firm knowledge of all things <biblScope> and <pb> as this situation is a little tricky. In cases where we have an image of a letterbook
copy and an original copy of a given correspondence, we privilege the original, and
comment out the letterbook-related tagging (see example below).
Please note that, typically, the letterbook versions of the correspondence appear
in the 398/1 and 410/1 collections, at least as of this writing. This potentially
complicated process is best illustrated by way of example, in which all text is black
except the markup for the original documents’ metadata and content appears in blue, the markup for the letterbooks’ metadata and content appears in red, and the green to indicate new comment for document revisions:
As you can see, we comment out the former tags, rather than delete them. This allows us to ‘awaken’ them in some fashion, should we choose to in the future.
We place the old image referent in parentheses, however, to indicate to readers that
a given file is based on an alternative image collection, as in the following example
taken from above:
NAC, RG7, G8C/6, p. 156(CO 398/1, p. 87)
Ask a team member to supply you with a copy of the “Double-image Gumbo” the text file which is an assortment of useful text that can be dragged into the
XML document during this process. You’ll need to change the data from despatch to
despatch accordingly. For example, changing “<idno type="page">??? </idno>” to “<idno type="page">156</idno>.”
If there aren’t any source images for the original documents, make a comment that
explains that we only have the letterbook copy and proceed with <pb> tags as you would normally. Or, conversely, if we only have original images and no
letterbook, do the opposite (but in this case we likely don’t have a transcribed XML
which means we need to create one and that’s an entirely different story… this doesn’t
happen often, thankfully).
6.9.9.1. Add formerly missed enclosures to an XML file
This section addresses the problem of what to do when you find an enclosure, or “other file,” that Jim’s team failed to add to the XML file. We put this section here as, most
of the time, you will find missed files when you replace a letterbook transcription
with an original (described in the section above).
Jim and his team likely missed a given enclosure because they were working from letterbook
copies (the “CO 398” file family in our image collection).
Here’s the steps, with an example to follow:
<Add a div type="other_files"></div> tag. IMPORTANT: place this tag before the closed </body> tag, otherwise your content will appear outside the “body” of the text, which is
bad.
Within the <div type="other_files"></div> tag, add a <div type="other_entry"></div> tag.
Add your <pb> tag to the right of the open <div type="other_entry"> tag. See example screenshot below.
Within the <div type="other_entry"></div> tag, add an <ab></ab> tag. This tag will contain your content. Think of it as analogous to a <p> tag.
Read through the letter as you will have to summarize its contents!
Final step? Imitate the format and phrasing in the following example:
<ab><name key="elliot_tf">Elliot</name> to <name key="hamilton_ga">Hamilton</name>, <date when="1863-03-04">4 March 1863</date>, forwarding copy of the despatch and recommending payment of the bill.
</ab>
Here’s an example from the letters:
<div type="other_files"><div type="other_entry"><pb n="co_60_15/co_60-15-00024r.jpg"/><ab><name key="elliot_tf">Elliot</name> to <name key="hamilton_ga">G.A. Hamilton</name>, <date when="1863-03-04">4 March 1863</date>, Treasury, forwarding copy of the despatch and recommending payment of the bill.
</ab></div></div>
6.9.10. Duplicate content in separate XML files (originals versus letterbook copies)
This section addresses the relatively rare cases in which we have two XML files that
contain the same content, with one being the original and one a letterbook copy. Here's
what we do in such cases:
Keep both files
Note in the abstract of each that the other file exists
In the abstract note, provide a link to each file, respectively
In general terms, we could delete the letterbook copy, and may decide to do this eventually.
For now, though, it makes sense to keep both files, as it’s reasonably quick to add
notes to the abstracts of each file. As of this writing, 1859 is the only year that
contains both original and letterbook versions as separate files.
For the “xml:id” value, please use the despatch that you’re currently working with, an underscore,
then a unique number, as shown in the above example.
6.9.11.1. What to tag, or not, in notes
First, some background. On the Despatches website, notes appears as a pop-up over the area that corresponds to the note button.
In addition, the notes in the pop-ups appear, as “footnotes,” at the bottom of the page.
Names
Places
Vessels
Dates
Do not tag the following:
Anything that is already part of a link (any content within a <ref> tag of any kind), as in the following example:
In the example above, note that ‘Douglas’ has been incorrectly tagged (it appears with a dashed underline) in what is already
a link (the green text). So, if you were to click on ‘Douglas’—the link within the link—things break and get screwy, as the site is not setup to
handle links within links. In the XML code the incorrect code looks like this:
<ref target="cdc:B58001#B00101">12719, CO 60/1, <name key="douglas_j">Douglas</name> to Lytton</ref>.
Bibliographic information within <note> tags. For example, this citation appears within a <note> tag in the B58008.scx file: <title level="m">The Statutes of the United Kingdom of Great Britain and Ireland. 14 & 15 Victoria</title>. 1851 (London: Her Majesty's Printers, 1851). Notice that ‘Victoria’ and ‘London’ do not have tags, as they’re part of the reference, not the content of the despatch.
6.9.12. Okina: the Hawaiʻian character
Not quite an apostrophe, not quite a left-facing single quote, the ʻokina serves as
a glottal-stop indicator in Hawaiʻian. The Unicode character is U+02BB and the HTML
Entity (decimal) is as follows:
This section refers to an instance in which the author quotes someone else with quotation
marks, and it’s clear as to where the quote begins and ends, however, the author has
added an open quote on each quoted line. Here’s a good example as it would appear
in the despatch actual:
Now I understand Mr Stephen to be of opinion that to give the Company "a "new interest & title in Land in these "regions would be said to be an attempt "to prolong beyond 1859" (when the present…
We’ll hide the superfluous quotes for the sake of readability, and to reduce confusion,
but we’ll tag them in such a way that we can display them should we wish to, as follows:
Now I understand <name key="stephen_j">M<hi style="superscript_underscore">r</hi> Stephen</name> to be of opinion that to give the Company "a <choice><orig>"</orig><reg/></choice>new interest & title in Land in these <choice><orig>"</orig><reg/></choice>regions would be said to be an attempt <choice><orig>"</orig><reg/></choice>to prolong beyond 1859" (when the present…
Note: Regular quotations will still use <q> and <soCalled> tags.
6.9.14. Sex attribute
This attribute is a way in which we handle whether or not a given person is male,
female, or gender neutral. We use these tags so that researchers can obtain data on
all of the women, men, or people who are gender neutral. For now, this attribute has
been applied to women only, and in the biography files. Here’s an example from the
1860 biographies file:
For sex values we use The International Organization for Standardization (ISO) ISO/IEC 5218.
The four codes specified in ISO/IEC 5218 are:
0 = not known
1 = male
2 = female
9 = not applicable
NOTE: The numeric value of “2” for women means that they’re worth twice as much as a man.
6.9.15. Scribal filler
We need a way to handle the more bizarre and arcane textual marks produced by the
various cursive eccentricities of the despatch authors. One in particular gave us
recent trouble (see image below):
Rather than download and install a whole new TEI module, we used a wave dash, with
an accompanying note, as seen in the following example:
<note xml:id="v465HB02_2">This is a scribal filler, likely used to denote the continuation of a given paragraph.
This representation is approximate; see corresponding image scan for the original
mark.</note>
Here’s a wave dash that you can copy: 〜
6.9.16. Horizontal line extension
This one is used generally at the end of sentences. It seems to serve, in the despatches
at least, the purpose of a period and a dash simultaneously, as in this example:
Add this HTML entity to your XML document as needed:
⎯
Please note that some browsers display this as an underscore ( _. )
6.9.17. To [sic] or not to [sic]
It may be appropriate, in some cases, to use [sic] to indicate what you see as a clear error in meaning or word choice. Always run
your [sic] moves past your colleagues for approval and discussion. We also need to indicate
the correction in order to give the reader the choice. As it stands, we follow the
TEI Guidelines on such cases, which states the following:
It’s also possible, using the <choice> and <corr> elements, to provide a corrected reading:
I don't know, Juan. It's so far in the past now — how <choice><sic>we can</sic><corr>can we</corr></choice> prove or disprove anyone's theories?
It’s also possible to indicate the level of confidence one has in a given editorial
change. We may want to consider the following as an option:
An <choice><corr cert="high">Autumn</corr><sic>Antony</sic></choice> it was, That grew the more by reaping
Further reading on apparent errors can be found here.
When a correction is made using these tags, indicate your responsibility for it using
your initials:
This is <choice><sic>probly</sic><corr resp="mdh">probably</corr></choice> wrong.
Normal TEI practice would use a hash (#) before the resp attribute and point it at
a full person reference in the header of the file, but for the moment we'll keep in
simple and just use initials. At some point, we'll probably start building a list
of bios for the people involved with the project, and we can easily transform hashless
initials into hash pointers then (when there's something to link to).
It may be appropriate, in some cases, to use [sic] to indicate what you see as a clear
error in meaning or word choice. Always run your [sic] moves past your colleagues
for approval and discussion. We also need to indicate the correction in order to give
the reader the choice. As it stands, we follow the TEI Guidelines on such cases, which states the following:
It’s also possible, using the <choice> and <corr> elements, to provide a corrected reading:
I don't know, Juan. It's so far in the past now — how <choice><sic>we can</sic><corr>can we</corr></choice> prove or disprove anyone's theories?
It’s also possible to indicate the level of confidence one has in a given editorial
change. We may want to consider the following as an option:
An <choice><corr cert="high">Autumn</corr><sic>Antony</sic></choice> it was, That grew the more by reaping
Further reading on apparent errors can be found here.
When a correction is made using these tags, indicate your responsibility for it using
your initials:
This is <choice><sic>probly</sic><corr resp="mdh">probably</corr></choice> wrong.
Normal TEI practice would use a hash# before the resp attribute and point it at a
full person reference in the header of the file, but for the moment we'll keep in
simple and just use initials. At some point, we'll probably start building a list
of bios for the people involved with the project, and we can easily transform hashless
initials into hash pointers then (when there's something to link to).
6.9.18. Strange strings, funny tags, and other legacy issues
This section is for examples of strange tags and the like, which occurred when we
transformed the old digital collection from Waterloo script to XML. In simple terms, think of these instances as ghosts in the code. We handle
them on a case-by-case basis. Please add to this list as you encounter new quirks.
<note xml:id="B00501" n="B5800501"/>
Keep the tag above as is. Our <note> tags don’t look like them. These are leftovers from the notation that Jim and his
team added to, mostly, the 1858 despatches. These don’t seem to break the site (the
notes work online) so we’ll leave them as is for now. Last count: over 600 instances,
mostly in the 1858 files.
<milestone unit="section" rend=".in -10 +0"/>
Ignore <milestone> tags. We see these <milestone> tags from time to time, and in various forms. Generally, they mark instances of tables,
or table-like things. Please leave them alone. We’ll use them at some point, even
if it’s to replace them with proper XML tables.
6.9.19. Superscript and abbreviation conundrums
Often, the despatch authors abbreviate to save space and ink, and to annoy you personally.
In so doing, they can be a little ham-handed in their cursive when it comes to indicating
distinctly whether they intend a superscript, an abbreviation, a superscripted period,
or an underlined superscript. As a general rule, we try to represent the text as closely
as possible. So here’s a list of some common confusers, and how to handle them:
(1) Text is clearly smaller and floating above the usual cursive line, usually at the end of a word: use only a superscript tag.
(2) Text is clearly smaller and floating above the usual cursive line, but it has
a single line or dot below it: this is likely to indicate a line, or underscore, under the superscript. The author
intends to make it clear to the reader the presence of a superscript, so we reproduce
this as follows:
(3) Similar to (2), but it’s clear that the single dot is to the right of the superscripted
letter or letters, and in line, or thereabouts, with the main text: this is likely
a period to indicate an abbreviation, so follow this example (note that the period
is to the outside of the superscript tag):
(4) Similar to (3), but the period is on the same level as the superscript: place
the period inside the superscript tag in order to superscript the period, as in the
following example:
(5) Text is clearly smaller and floating above the usual cursive line, but it has
two lines or dots below it, or a dot and line in an unclear order or location: use
your judgment, based on the examples above.
Of course, many intentions are possible. Likely, though, two lines, dots, or marks,
in any configuration are meant to indicate an underscored superscript, followed by
period to indicate an abbreviation. When in doubt ask for a second opinion.
6.9.20. Transcribed minutes on “enclosures” and on “other files”
Note that transcribed minutes that appear on enclosures will not be within a <div type="minutes">, they will appear only as <div type="minute_entry">; we so because we want the minutes to appear online as though they’re under the “Documents enclosed with the main document (not transcribed)” divider.
If the transcribed minutes appear on the first page, then DO NOT insert a <pb> tag.
If the transcribed minutes occur on subsequent pages, then insert a <pb> tag that links to the page that contains the minutes; if, in these minutes, the text
covers multiple pages, then insert <pb> tags at each page beginning, as you would for the despatch letters.
6.9.21. type=unavailable vs. incomplete
This value is added to people, place, or vessel entries that are either incomplete
or unavailable. Here’s the current meaning for each:
unavailable means that we’ve added no information to the entry, just its name, place name, or
vessel name, respectively.
incomplete means that we’ve added cursory information to a given entry, but it reads as unfinished,
and therefore needs more research and content.
In the biography entries, use the following tags:
<persName type="unavailable"/>
<persName type="incomplete"/>
In the places entries, use the following tags:
<placeName type="unavailable"/>
<placeName type="incomplete"/>
In the vessel entries, note that things change slightly, and the attribute value has to be added
as a “subtype” to be valid:
This tag is used to handle text that’s too garbled or difficult to make out. Typically,
since Jim and his crew were so good at transcribing the original text, you’ll end
up using this tag infrequently. Should you need it, it’s as follows:
<unclear>content here</unclear>
6.9.23. Wavy or squiggly lines and underlines
This situation is a little tricky and should be handled on a case-by-case basis. Here’s
an example of a need for squiggly lines:
The Unicode name for squiggly lines is “wavy low line.”
Copy this symbol to your XML document as needed: ﹏
Remember that each “﹏” will only fill the width of one character space. It takes quite a few to make a line!
7. Colonial Despatches style guide
7.1. Abbreviations
Currently, the only abbreviation for organizations that we use is HBC (Hudson’s Bay
Company). CMOS recommends that less familiar abbreviations aren’t to be used unless the word appears
more than five times (see CMOS 10.3).
We use abbreviations for metric (km, m, cm) and write out imperial (mile, foot, inch).
We do not, however, use an abbreviation for “street.”
CMOS recommends that periods are generally not to be used in abbreviations (see CMOS 10.4). Periods are only used in abbreviations that end in a lower case letter (vol., a.m.,
p.m., Mr., Ms.), except for measurements.
Initials standing for given names are followed by a period and a space. A period is
normally used even if the middle initial does not stand for a name (as in Harry S.
Truman).
Roger W. Shugg
P. D. James
M. F. K. Fisher
If an entire name is abbreviated, spaces and periods are usually omitted.
FDR (Franklin Delano Roosevelt)
MJ (Michael Jordan)
but
H.D. (pen name for Hilda Doolittle, with periods but no space between initials because
it’s a special case)
7.1.2. Abbreviations of provinces, territories, and states
Provinces, territories, and states are spelled out in text. Abbreviations may be used
in bibliographies using the two-letter postal abbreviations (see CMOS 10.28).
In running text, spell out “British Columbia” as a noun; reserve “BC” for the adjective form only (see CMOS 10.32). We don’t place periods around “BC” either (see CMOS 10.4).
7.2. Ellipses
From the CMOS 13.50: Ellipses defined: “An ellipsis is a series of three dots used to signal the omission of a word, phrase,
line, paragraph, or more from a quoted passage.” Most often, we use ellipses to indicate that we have removed a portion of text.
Use the following HTML entity (horizontal ellipsis) in your XML document: …
Or, copy/paste this example ellipsis into your XML document:
…
Add ellipses with no spaces either side of the text. We treat each ellipsis as we would an em-dash, with no spaces either side of the
punctuation. Our style does not follow the CMOS style, where an ellipsis is "three spaced periods" (see 13.50: Ellipses defined) with spaces either side of the ellipsis. We think it simpler to use the Unicode
character ….
Ellipsis usage:
Within a sentence:
I report that the ship…has landed at the expected port.⚓
The spirit of our ship is sound…. On the other hand, the crew has become indolent.⚓
In brackets, we add spaces preceding and following the bracketed ellipses:
The crew decided then…to make […] all the the grog vanish that night.⚓
Use bracketed ellipsis only in cases of disambiguation, that is, where the original
sentence has ellipses and you have also omitted text, as in the example above.
We use bracketed ellipsis in citations, usually to shorten long titles:
Baggins, Frodo. A Discourse on Elves, Dragons, and Packing Advice for Middle Earth […]. The Shire, 2942.⚓
In this, we follow the suggestion in CMOS 14.97: ‘Very long titles may be shortened in a bibliography or a note; indicate such omissions
by the use of bracketed ellipses."’. Note that the "[…]" is not in italics, as it is not part of title.
In parentheses, we add spaces preceding and following the parenthetical ellipses:
"The next day, the crew was (…) royally hungover."
More CMOS ellipsis usage:
13.53: Ellipses with periods: ‘Note that the first word after an ellipsis is capitalized if it begins a new grammatical
sentence. Some types of works require that such changes to capitalization be bracketed;
see 13.21. See also 13.58.’
Oxford, or serial, commas are used in all Despatches writing. We do so to avoid ambiguity, as CMOS 6.19 suggests.
Oxford/serial commas are used “when a conjunction joins the last two elements in a series of three or more.” The comma is placed before the conjunction. For example, “she posted pictures of her parents, the president, and the vice president.”
7.4. Punctuation inside or outside of quotation marks?
Punctuation like periods and commas go inside of quotation marks, while punctuation
like question marks and exclamation marks go either inside or outside depending on
the content of the quote.
See this table from CMOS, section 6.1:
7.5. Blockquotes
Chicago differs from MLA in this respect in that MLA calls for blockquotes for quotes over four lines in length. CMOS, however, advises blockquotes for a hundred words or more (at least six to eight
lines of text in a typical manuscript), unless “quotations are being compared or otherwise used as entities in themselves” (see CMOS 13.10).
The latter instance is a judgment call, of course, and if you’re unsure, please consult
your Despatches colleagues.
Finally, see the CSS: block quotations section for how to tag your blockquotes in XML.
7.6. Preferred spelling
Use Canadian spelling in all cases except for “despatch” (not “dispatch”). Below is a word list to help you with the correct spelling for Despatches. Please consult your Despatches colleagues if you think a word should be added to the list.
Remember, correct spelling includes correct capitalization and hyphen use. When in doubt,
here’s a reliable source for Canadian spellings: The Canadian Oxford Dictionary (requires login on a computer outside of the library). Luke Mastin’s Canadian, British and American Spelling website is also a helpful tool, but make sure to double-check the preferences on the website
against the COD or this list since there are a few inconsistencies.
7.7.1. Capitalization of cities, towns, forts, and political divisions
Words like empire, confederation, province, fort, and town are capitalized when they
follow a proper name and are used as an accepted part of the name. When preceding
the name, such terms are usually capitalized in names of countries but lower case
in entities below the national level (see CMOS 8.51).
Examples (add more as they occur):
the province of Ontario
Massachusetts Bay Colony; the colony at Massachusetts Bay
the Indiana Territory; the territory of Indiana
the Northwest Territory; the Old Northwest
New York City; the city of New York
the British Empire; the empire
When a specific government body or organization is meant rather than the place, the
government body is also capitalized—for example, he worked for the Province of Ontario
(see CMOS 8.52).
7.7.2. Capitalization of directions
Compass points are not capitalized when they are used to explain directions such as
“to the north of Vancouver” or “eastern Canada.” However, compass points are capitalized when they refer to places such as “North Vancouver” or “East Canada” (see CMOS 8.47). Further examples include the following: “he went to the West Coast for his holiday,” but “he went to British Columbia's west coast.”
7.7.3. Capitalization of ethnic and other national groups (Indigenous, Aboriginal, First
Nations)
Ethnic and national groups are capitalized. Adjectives associated with these names
are also capitalized (see CMOS 8.38 and the UVic Style Guide Section 5.2).
7.7.4. Capitalization of military and other titles
As for military titles, we’ve settled on CMOS's approach to this matter: “in formal academic prose, most such titles are capitalized only when used as part
of a person’s name” (see CMOS 8.24).
Some pertinent examples are as follows, as taken from CMOS 8.24:
the admiral; Chester W. Nimitz, fleet admiral; Admiral Nimitz, commander in chief
of the Pacific Fleet; the captain; Captain Frances LeClaire, company commander
the sergeant; Sergeant Carleton C. Singer; a noncommissioned officer (NCO)
the British general; General Sir Guy Carleton, British commander in New York City;
General Carleton.
As for other titles, such as nobility, CMOS states the following:
Unlike most of the titles mentioned in the previous paragraphs, titles of nobility
do not denote offices (such as that of a president or an admiral). Whether inherited
or conferred, they form an integral and, with rare exceptions, permanent part of a
person’s name and are therefore usually capitalized. The generic element in a title,
however (duke, earl, etc.), is lowercased when used alone as a short form of the name.
Some pertinent examples are as follows, as taken from CMOS 8.32:
the prince; Prince Charles; the Prince of Wales
the duke; the duchess; the Duke and Duchess of Windsor
the marquess; the Marquess of Bath
Lord Bath; the earl; the Earl of Shaftesbury; Lord Shaftesbury; Anthony Ashley Cooper,
7th (or seventh) Earl of Shaftesbury; previous earls of Shaftesbury.
See CMOS 8.32 for more, particularly on the differences with British usage.
7.7.5. Capitalization of places
Names of places, including mountains, rivers, islands, etc., are capitalized. In cases
where terms like “mountain,”“ocean,” and “river” are included in the name of the place they are capitalized as well. See CMOS8.47 to 8.58 for clarification.
Examples:
the Pacific Station
Bamfield Inlet
the Gulf
Greater Victoria
the City of Victoria
the metropolitan area
the United States
the republic
the Union
the river Fraser
Fraser River
London Bridge
the Pyramids
the Egyptian pyramids
the West Wing
7.7.6. Capitalization of political parties
Official names of political parties and organizations are capitalized. Words like
“party,”“union,” and “movement” are capitalized as well if they are included in the name of the political party or
organization. See CMOS 8.66 for clarification.
Examples:
Whigs [except when used as as adjective, as in, ‘he behaved whiggishly.’]
Tories
the Democratic Party
democratic nations
Loyalist(s)
7.7.7. Capitalization at the start of quotations
Capitalization within quoted material can be changed to suit the context (within reason).
These changes can be made “silently,” that is, they don’t require square brackets to indicate that a change has been made
since the meaning and word choice of the quoted material remains the same. See CMOS13.18 and 13.7 point three for clarification.
Example: After his stint in politics, and, with his children either abroad or “leading frivolous lives,” Dunsmuir retreated to a solitary life on his estate at Hatley Park.
7.8. Sentence case for headers
The Despatches team have come to an agreement that all headlines will be in sentence case rather
than title case. Sentence case in a header is indicated by the capitalization of the
first word and proper nouns only, for instance you would write: “Blurb about sentence case” rather than “Blurb about Sentence Case.” So why is this the better option?
Sentence case is actually the style that is internationally used. Title case has really
only been adopted in the “North American” context, so the Despatches are hopping on the bandwagon! Therefore, by using sentence
case, it makes it more accessible to a wider audience to read, understand, and note
what is a proper noun and what is not. While we are at it, let’s discuss more reasons
why sentence case is better…
Google uses sentence case due to its superior readability, tone, functionality, and
comprehension. So, as mentioned before, it will reach a broader range of people. In
this view, sentence case is superior because it is the natural way we read. How crazy
would it be if we were reading a book like this: “Once Upon a Time There was a Little Bird…” In this way, sentence case is a simple and organic way to read for the human mind.
Simply, sentence case is: easier to write, easier to read, and easier to translate.
Last but not least, it has been stated by many people who prefer sentence case, that
it has an approachable tone. What this means is that it is less bold and “in your face” as title case can be (which does have its own perks); but it creates a connection
with the people reading it. One could say that in this way, sentence case creates
a universality through the way that it is written.
7.9. Comma with city plus province/state
When following the name of a city, whether spelled out or abbreviated, the names of
states, provinces, and territories are enclosed in commas (see CMOS 10.29). For example: Victoria, BC, is a nice city.
7.10. Periods in a list
Periods should only be used at the end of a bullet or list point if the point contains
a full sentence. If the point is a phrase then a period is not used.
7.11. Hyphens
Hyphens are tricky--CMOS provides a comprehensive hyphenation table that can be used to answer most questions.
Here are a few common issues of proper hyphenation:
Canada-US border (not Canada/US border)
4 km wide river (not 4-km-wide river)
7.12. Newspaper titles
Omit the “the” from newspaper titles. For example, write the British ColonistnotThe British Colonist. See CMOS 14.193 for more.
Don’t forget to italicize newspaper titles. Be sure to wrap them in a <title> tag, as in the following example:
edition of the <title level="j">British Colonist</title> gives notice
Note: as stated above, “the” is left outside of the <title> tag.
7.13. Numbers: to write out or not?
Spell out numbers from zero through nine, use a numeral for 10 and above (see CMOS 9.3).
Try to avoid starting a sentence with a number. If you have to, spell out the number
that starts the sentence (see CMOS 9.5).
When an abbreviation is used for a unit of measure (i.e. km, m, cm), then the quantity
must always be expressed by a numeral (see CMOS 9.16).
7.13.1. Words versus monetary symbols and numerals
Isolated references to amounts of money are spelled out for whole numbers of one hundred
or less (see CMOS9.2 and 9.3).
Examples:
Correct: $100,000
Correct: Ten dollars
Incorrect: 100,000 dollars
Incorrect: $10
7.14. Possessives and attributives
CMOS has changed the convention of correct singular form possessives (see CMOS 7.17). For example, instead of “Douglas’ letter” it’s now “Douglas’s letter.” This rule includes nouns that end in a silent “s,” such as “Descartes’s three dreams” (see CMOS 7.18).
Note: plural possessives continue as before with an apostrophe alone. For example, “the Lincolns’ marriage.”
7.15. Roman for Latin words and abbreviations
Unlike most words in a foreign language, commonly used Latin words and abbreviations
should not be italicized.
Examples: Ibid., et al., ca., passim
However, “sic” should be italicized due to its distinct use in quotations. For example, “mindful of what has been done here by we [sic] as agents of principle” (see CMOS 7.55).
7.16. Ships and other named vessels
Names of ships and vessels are capitalized and italicized. The word “ship,” or other vessel types, should not be used in cases where the abbreviations USS (United States ship) or HMS (Her or
His Majesty’s ship) precede the name of the vessel. These abbreviations aren’t italicized
either.
Mars global surveyor; Mars polar lander; Phoenix Mars lander; Phoenix
the space shuttle Discovery
the Spirit of St. Louis
HMS Frolic; the British ship Frolic
SS United States; the United States
USS SC-530; the US ship SC-530
7.17. Speeds
As ever, we list speeds in metric. Here’s an example:
Knots (ship speed measurement) should be converted to “kmh” (kilometres per hour),
as in 22 kmh.
7.18. XML style preferences
7.18.1. <soCalled> and <q> tags
<soCalled> elements are used for nicknames, scare quotes, terms in Indigenous languages, and
informal event names (e.g. Pig War). <q> elements are used to replace quotation marks around quotes. <q> elements can also be nested in instances where there’s a quote within a quote.
Company and store names do not have quotation marks around them. The same rule applies for instances of Her Majesty
and places (unless an informal name is used).
Unfortunately, the area was leased to the Hudson’s Bay Company at the time and the
Colonial Office could not <q>undertake to say on which terms land shall be offered in that island</q> and declined his request.
his body was found with <q>a Bag Containing Gold Dust value 69 Dollars and 50 Cents--In Silver Coin One Dollar
& 85 Cents and a <q>Colt Revolver</q>,</q>
Here’s some examples of <soCalled> tags used to indicate informal terms/names:
However, in 1856, Walker did become president of Nicaragua and implemented an <soCalled>Americanization</soCalled> program to encourage U.S. citizens to immigrate there.
The water boundary issue resulted in what is now known as the <soCalled>Pig War.</soCalled>
Here’s an example of the <soCalled> tag used for a term in an Indigenous language. Note that the tag is used around the
term and its English translation:
The Lummi named the area <soCalled>what-coom</soCalled>, or <soCalled>noisy, rumbling water</soCalled>, in reference to a waterfall near Bellingham Bay.
7.18.2. Canadian vs. American spelling in tags
Note that tags often use American spelling preferences. While we use Canadian spelling
like in “centre” throughout running text, “center” needs to be used when marking up text in Oxygen.
For example:
<hi style="text-align:center;">He stood in the centre of the crowd.</hi>
7.19. In-text date format
For dates within the text of our writing we break from CMOS and use MLA "humanistic"
style of formatting which is integer of day, month spelled out, and integer for year.
(For a streamlined version of this section and workflow directions specific to the
Professional Communication Directed Reading program please see the Colonial Despatches Directed Reading document.)
Since there are so many authors working on the Despatches website, we want to keep
the writing consistent. With this in mind, here’s a working list to consider when
you begin writing:
Know the difference between (1) direct quotation, (2) paraphrasing, and (3) summary.
Honestly, if you’re shaky on any of this then you should probably not write anything
until you have it dialed in.
Use last names when you refer to a person after their full name has been mentioned
once already. For example, write ‘Douglas reports that’ not ‘Governor Douglas’ or ‘James Douglas’ after the first instance of ‘Governor James Douglas.’
Avoid parenthetical interjections (like this), use commas, em dashes, or rework the sentence.
Do NOT put double spaces between sentences! And don’t use double returns between paragraphs.
8. Chicago-style citations
8.1. Our reference system: Chicago-style endnotes
When website readers click on tagged person, place, or vessel, a pop-up note appears,
in order to provide for the reader further context. These pop-up notes are well-researched
mini essays of a sort, and cited as one would an academic essay. However, these pop-ups
are neither truly notes nor essays exactly, so we treat them as Chicago-style“notes,” as this is the closest definition we can all agree upon.
When in doubt about anything to do with this decision, refer to your Despatches colleagues or refer to the CMOSwebsite as needed.
8.2. Notation numbers
Each notation number should have a corresponding endnote at the end of the entry.
Here is what a typical note looks like on the website (circled in red):
The notation numbers in a given entry should appear in numerical order from top to
bottom. Numbers are to be placed to the right of the period, and any other punctuation,
e.g. outside quotation marks. No notation number mid-sentence please. Colonial Despatches
prefers all notations at the end of sentences (indicating more than one source if
necessary).
XML code placeholder for a number (copy/paste):
<bibl corresp="#xml:id_b_corresponding number here"><hi style="vertical-align: super; font-size: 80%;">number goes here</hi></bibl>⚓
Each endnote should have a corresponding number notation in the entry. We use this
system as it makes for improved readability, as opposed to, say, MLA, in which each
reference requires a parenthetical citation at the end of the sentence. This latter
system can look pretty cluttered in such a small chunk of text. These endnotes will
have corresponding <bibl> tags that link to the note in the text by using a unique xml:id in the form shown
below, with the note content inside.
XML code placeholder for an endnote (copy/paste):
<bibl xml:id="xml:id here_b_number of endnote here">Citation here.</bibl>⚓
Example from the V60 bios:
<bibl xml:id="allison_b_3">3. <ref target="cdc:B60070">Douglas to Newcastle</ref>, 3 August 1860, 9346, CO 60/8, 2.</bibl>
8.3.1. Endnote punctuation and formatting minutia
This section is intended to show you how to punctuate and format your endnotes and
bibliography entries. Here are some endnote and bibliograpy punctuation rules, in
no particular order:
<title> tags with an attribute of level="a" should appear after, or outside, punctuation marks. Here is an example from a <bibl> entry for a journal:
<bibl xml:id="shifting_perspectives_b_6">6. Eve Tuck and K. Wayne Yang, <title level="a">Decolonization Is Not a Metaphor,</title><title level="m">Decolonization: Indigeneity, Education & Society</title> 1, no. 1 (2012): 6.</bibl>
Note that if we wrap a <ref> tag around an article title, we place the <ref> tag inside the <title> tags, but before the comma:
<bibl xml:id="shifting_perspectives_b_6">6. Eve Tuck and K. Wayne Yang, <title level="a"><ref type="external"
target="https://jps.library.utoronto.ca/index.php/des/article/view/18630/15554">Decolonization Is Not a Metaphor</ref>,</title><title level="m">Decolonization: Indigeneity, Education & Society</title> 1, no. 1 (2012): 6.</bibl>
<title> tags with an attribute of level="m" should appear before, or inside, punctuation marks. This is because wrapping text
in a level="m" tag renders as italics, not quotation marks, on the website. Here is an example from
a <bibl> entry for a book:
<bibl xml:id="indianact_b_5">5. Bob Joseph, <title level="m">21 Thing You May Not Know About the Indian Act: Helping Canadians Make Reconciliation
with Indigenous Peoples a Reality</title> (Port Coquitlam: Indigenous Relations Press, 2018), 94.</bibl>
8.3.2. Examples of endnotes
8.3.2.1. Book and monograph example
<bibl xml:id="carrall_ww_b_8">8. Tom Snyders and Jennifer O'Rourke, <title level="m">Namely Vancouver: The Hidden History of Vancouver Place Names</title>, (Vancouver, BC: Arsenal Pulp Press, 2001), 57.</bibl>
8.3.2.2. Journal article example
<bibl xml:id="onslow_b_4">4. Barry M. Gough, <title level="a"><ref type="external"
target="http://www.jstor.org/stable/4049600?seq=12">The British Reoccupation and Colonization of the Falkland Islands</ref></title>, <title level="m">Albion: A Quarterly Journal Concerned with British Studies</title>, 22 (Summer 1990): 271-272.</bibl>
8.3.2.3. Despatch example
<bibl xml:id="pike_b_4">4. <ref target="cdc:V635AD01">Paget to Rogers (Permanent Under-Secretary)</ref>, 29 June 1863, 6392, CO 305/21, 3.</bibl>
This is what the above example looks like on the website:
8.3.2.5.2. Web page, no author
<bibl xml:id="alarm_b_2">2. <title level="a"><ref type="external"
target="http://www.pbenyon.plus.com/18-1900/A/00134.html#Expedition">Alarm</ref>, </title><title level="m">Index of 19th Century Naval Vessels</title>.</bibl>
This is what the above example looks like on the website:
8.3.2.5.3. Web page, PDF
In the following example, we have a PDF link, that links to a PDF that has page numbers:
<bibl xml:id="bruce_b_1">1. <title level="a"><ref type="external"
target="http://www.proni.gov.uk/introduction_hervey_bruce-2.pdf">Hervey/Bruce Papers</ref></title>, <title level="m">Public Record Office of Northern Ireland</title>, 15.</bibl>
8.3.2.6. Online dictionary or biography
In the following example, we have an online dictionary or biography:
<bibl xml:id="chesson_fw_b_1">1. H.C. Swaisland, <title level="a"><ref type="external"
target="http://www.oxforddnb.com/view/article/38853.">Chesson, Frederick William</ref></title>, <title level="j">Oxford Dictionary of National Biography</title>.</bibl>
8.3.3. Archival sources
For archival material, we use a format based off of Chicago style. Begin with the
name of the archive, followed by the title of the document, marked up with <title level="u">, then add the additional document information.
Below is an example from the Library and Archives Canada (LAC). Note that
<bibl xml:id="shrapnel_h_b_1">1. LAC, <title level="u">Commissions of Henry Needham Scrope Shrapnel</title>, MG 24 F 113, Vol 3, File 1.</bibl>
8.3.4. Multiple citations
Note that we don’t include the pop-up content in the following example. It’s presumed
that the notation numbers are added correctly.
<listBibl><bibl xml:id="smith_w_b_1">1. Hubert Howe Bancroft, <title level="m">The Works of Hubert Howe Bancroft. Volume XXXII. The History of British Columbia.
1792-1887</title>, (San Francisco: The History Company, Publishers, 1887), 617.</bibl><bibl xml:id="smith_w_b_2">2. Milton, William Fitzwilliam, viscount, <title level="m">A History of the San Juan Water Boundary Question, As Affecting the Division of Territory
between Great Britain and the United States</title>, (London: Cassell, Petter, and Galpin, 1869), 256-257.</bibl><bibl xml:id="smith_w_b_3">3. <ref target="cdc:V59031">Douglas to Lytton</ref>, 8 August 1859, 9570, CO 305/11, 29.</bibl></listBibl>
8.3.5. Multiple citations in one note
Always use one number to indicate multiple sources, but add a semicolon between the
sources in the <bibl> entry, as in the following example:
<bibl xml:id="anderson_d_b_4">4. S. Van Kirk, <title level="m">Women in Fur Trade Society in Western Canada, 1670-1870</title>, (Winnipeg: Watson & Dwyer Pub., 1980), 220-30; F. Pannekoek, <title level="m">A Snug Little Flock: The Social Origins of the Riel Resistance, 1869-70</title>, (Winnipeg: Watson & Dwyer Pub., 1991), 119-59.</bibl>
Here’s an example of what it will look like on the website (note that the double source
is number four):
8.3.6. Multiple and repeating citations
We don’t use short forms of sources when they repeat since it’s less work to simply
copy/paste the reference. Note that we don’t include the pop-up content in the example
below. It’s presumed that the notation numbers are added correctly.
<listBibl><bibl xml:id="shrapnel_b_1">1. <ref target="cdc:B606S01">Shrapnel to Newcastle</ref>, 4 April 1860, 3586, CO 60/9, 386; <ref target="cdc:B606S02">Shrapnel to Newcastle</ref>, 5 April 1860, 3872, CO 60/9, p.388.</bibl><bibl xml:id="shrapnel_b_2">2. <ref target="cdc:B606S02">Shrapnel to Newcastle</ref>, 5 April 1860, 3872, CO 60/9, 388.</bibl><bibl xml:id="shrapnel_b_3">3. Ibid.</bibl><bibl xml:id="shrapnel_b_4">4. <title level="a"><ref type="external"
target="https://www.warmuseum.ca/supplyline/wp-content/mcme-uploads/2014/10/CWM_SupplyLine_ShrapnelBullets_EN_FINAL_20140922.pdf">Artifact Backgrounder: Shrapnel Bullets</ref></title>, <title level="m">Canadian War Museum</title>; John Sweetman, <title level="a"><ref type="external"
target="https://doi.org/10.1093/ref:odnb/25473">Shrapnel, Henry</ref></title>, <title level="m">Oxford Dictionary of National Biography</title>.</bibl><bibl xml:id="shrapnel_b_5">5. Ibid.</bibl><bibl xml:id="shrapnel_b_6">6. John Sweetman, <title level="a"><ref type="external"
target="https://doi.org/10.1093/ref:odnb/25473">Shrapnel, Henry</ref></title>, <title level="m">Oxford Dictionary of National Biography</title>.</bibl><bibl xml:id="shrapnel_b_7">7. Ibid.</bibl></listBibl>
9. Abstracts
Abstracts are brief summaries of individual despatches, as well as the minutes, enclosures,
and other documents that occasionally accompany them. Abstracts are helpful research
tools that give viewers a sense of the main topics of a given despatch and allow them
to see if it aligns with their research or interests without having to read the entire
despatch.
Abstracts are notoriously difficult to write because they require a close reading
of the documents, an understanding of their relevance to the collection as a whole,
and their historical importance. Abstracts are highly subjective: what might seem
important to one of us might not be to others on the team. It is important that we
work together on the more complex documents, or whenever we have doubt about what
to include, or not, in our summaries.
There are two ways to access the abstracts on the Colonial Despatches website:
1. Select the ‘browse’ link in the main menu, where the despatches are ordered by year, and continue to
navigate to a despatch of a specific date:
2. Select the ‘Abstract’ link at the top of a given despatch:
9.1. Required skills
This section assumes that you have knowledge of the following:
How to tag content.
How to use the SVN repository, that is, commit your changes to the database.
A detailed understanding of the Colonial Despatches website and its various sections.
Familiarity with the structure and elements of a transcribed despatch as it appears
on the Colonial Despatches website, as well as the minutes, enclosures, and other documents that accompany it.
Proficiency in Oxygen (XML editor)- and a firm knowledge of the code and tags you will use during the markup
process.
An intermediate to advanced knowledge of 19th-century BC history.
9.2. Writing abstracts
Use Google Docs to draft your abstracts and share this document with your fellow editors, and ensure
that they have permissions to edit the file. Darth Google is evil, but Google Docs
allow for comments and feedback across platforms and editors. If you don’t know how
to work in Google Docs, then consult your Despatches colleagues who do.
As with all writing for this project, it’s essential that you take a look at the Style Guide section of this document before you begin. But we also have a special abstract style
guide below as well with some more specific conventions.
9.2.1. Before you write abstracts
9.2.1.1. Read the content (!)
It’s very important to read the entire despatch, as well as the attached minutes,
enclosures, and other documents, before you attempt to write your abstract. Because
certain topics tend to be the subject of multiple despatches, it’s helpful to read
the abstracts of the preceding despatch (or despatches) and, if time permits, those
of the previous year, in order to give you a better understanding of the topics of
your current despatch.
After you have read the despatch and all attached minutes, documents, and enclosures,
you may want to go through them again and take notes in order to get a basic framework
for your abstract. It’s a good idea to write the first draft of your abstract on Google
Docs and then copy/paste your content into the XML file once you or a Despatches colleague has proofread it.
9.2.1.2. Audience and voice
The target audience of the Colonial Despatches website is students, teachers, Indigenous scholars, professors, researchers, other
members of the academic community, history buffs, and lawyers.
As an academic site, all original written work, whether it be abstracts, biographies,
and vessel or place entries, should be written to university-level academic writing
standards. Concision and clarity are key. The main goal of an abstract is to summarize
despatch content with a purpose to inform, so please refrain from personal comments
or observations—this can be the most difficult part!
Remember that the role of the abstract is to describe what is being communicated, not what you or anyone else thinks about the communication.
Think of yourself as a reporter, describing what you see.
For voice, please apply the following:
Use present tense. For example, use “Douglas relates concerns about funds for roads,” and not“Douglas related concerns.”
Avoid passive voice. For example, “Douglas instructs the HBC to sell their Victoria properties,” and not“The HBC is instructed by Douglas to sell their Victoria properties.”
Avoid gerunds. Gerunds are formed by adding “-ing” to a verb, for example: “sleeping,”
“drawing,” “swimming.” But, they are not the “-ing” verb forms that you see in the
present or past continuous tense. They look the same, but gerunds are actually verb
forms used as nouns. We avoid them because they can cause confusion, especially in
cases where a gerund could be mistaken for a participle.
Repeat names to avoid confusion. For example, we could write that “Lytton informs
Douglas that his wig is, like, so eighteenth-century,” but it is not entirely clear
as to whom the “he” refers. In cases such as this, please repeat the name: “Lytton
informs Douglas that Douglas’s wig is, like, so eighteenth-century.”
Finally, write something that you would actually want to read.
9.2.1.3. Word count
The word count of an abstract will vary with the length of the despatch. In most cases,
use one paragraph for all content; however, if you have particularly long documents,
then you may need to write multiple paragraphs.
Smaller despatches should require only a few sentences. The word count for abstracts
of large despatches should not exceed roughly 200 words—anything over 200 words likely
requires revision. As for every rule, we expect exceptions, so if you’re stuck, or
unsure that you have captured the nature of the correspondence, please re-read the
document(s) to see if you can omit anything and still retain the main topics and overall
purpose for the correspondence. When in doubt, consult your colleagues.
9.2.2. Despatch structure walk-through
Colonial Despatches correspondence often contains three types of communication: (1)
the original despatch or letter, (2) minutes, and (3) attached documents (enclosures
or other files).
The following sections discuss what to include from each part of the correspondence
file:
9.2.2.1. The despatch, letter, or main correspondence
Include the following, where applicable, in your abstracts:
In the first sentence, include the author of the correspondence and the topic(s) of
the communication. (For further writing instructions see the Abstract Style Guide)
You may include other people, places, and subjects, important to the correspondence,
thereafter.
In a strange quirk of fate, the longer documents are often easier to summarize than
the shorter ones. Consult your Despatches colleagues as needed.
9.2.2.2. The minutes
We indicate to the reader already the number of minutes in a given correspondence.
Typically, we ignore minutes that discuss administrative procedures, such as “Put
by,” or “Send to Treasury.” However, should the minutes contain discussions, decisions,
or content of importance or of note, then please summarize them as you would an original
correspondence.
If you do include minute correspondence in your abstract, you can consult Gord's list
of Colonial Office staff and consultants, which is roughly ordered in a hierarchy
of the positions and who held them when, to get a better sense of who may be instructing
whom and when a staff member may likely be asking a question even though they make
no use of a question mark. Currently, it can be found here.
9.2.2.3. Enclosures and other files and attachments
We indicate to the reader already the number of attached documents in a given correspondence.
“Enclosures” are documents enclosed with the main document. “Other files” are included in the file or are associated with a given correspondence, but aren’t
considered part of the enclosures. For example, let's say a despatch encloses a list
of land owners on Vancouver Island. The Colonial Office receives this correspondence,
makes notes all over it (minutes), and sends it on to the Treasury, but, for the sake
of reference, adds a map to the file. The list of landowners would be the “enclosure,” but the map would be an “other file.”
Jim's team designated whether or not given correspondence was either an “enclosure” or an “other file,” and this convention is reflected in the tags we use to designate each in the XML
code. These codes are <div type="enclosure_entry"> and <div type="other_entry">, respectively.
Sometimes, “enclosures” can be misidentified as “other files,” and vice versa. To
get around this issue while describing the “enclosure” or “other file,” we use “document”
as a catch-all term. A “document” could be an “enclosure” or an “other file,” so we're
covered in terms of accurate language, without having to go back to the file later
and make corrections should, say, an “enclosure” turn out to be an “other file,” or
the reverse.
As a general approach, if the enclosures/attachments reflect the correspondences'
content, then we will ignore them in our summaries. In this sense, we assume that
readers who see, say, that a letter has 5 enclosures, will expect to find that the
enclosures pertain to the letter’s subject. However, if the enclosure/attachments
are somehow very different in subject, and interesting to you, or provide further context to the historical significance of the despatch, then mention
them.
For the enclosures and other files, use an opener such as “One of the included documents…” or “Included documents describe…”
In other words, keep it active, keep it safe. And, if anything above seems unclear,
please consult your Despatches colleagues.
9.2.2.4. Transcribed enclosures and attachments
The number of transcribed documents will be listed in the header metadata. Therefore,
it is not necessary to make any special mention of transcribed enclosures. Treatment
of these will fall under same guidelines and untranscribed enclosures. If the enclosed
or attached document is of significance and adds to the reader's unserstanding of
the despatch, a brief description of its contents makes sense. If not, the enclosure
can be ignored.
9.2.2.5. How to incorporate quotes from the correspondence
Think of the abstracts as miniature essays, and incorporate quotes as you would for
a university paper. In other words, put quotation marks around anything you pull,
verbatim, from the despatches! Here is an example. In this despatch, Douglas writes the following:
I am happy to inform your Lordship that nothing has occurred to disturb the tranquility
of the Settlements on this Island
If we summarized this line as follows:
Douglas reports to his Lordship that nothing has occurred to disturb the tranquility
of the settlements on Vancouver Island.
then, we would miss some necessary quotes, which would be added as follows:
Douglas reports to his “Lordship” that “nothing has occurred to disturb the tranquility of the Settlements” on Vancouver Island.
Quotes can serve a handy purpose when it’s difficult to discern exact authorial intention
or meaning, or when the writer's phrasing is necessarily specific. Take the following
example from Lord Grey's minute in this document:
It is better simply to say that I do not consider the charge to be one [which] ought
to be borne by the public.
We could say that “Grey does not want taxpayers to bear the cost,” but this statement is open to debate. Does he refer merely to the British tax base?
Or, does he refer to some other body? Would this be a colonial-only cost? It could
take considerable time to tease out exactly what Grey means, and heaps of research.
This is all well and good, but we’re supposed to be writing abstracts, not following
semantic breadcrumbs, seductive as that is. So, why not let Grey speak for himself,
in all his potential ambiguity? We could write the following:
Grey does not want the cost “to be borne by the public.”
Remember abstracts summarize, not speculate. What Grey writes is the most accurate representation possible. The incorporation
of quotes takes time to master. Be patient, and if you are unsure, then consult your
Despatches colleagues!
*Note: It is not necessary to quote words provided by other members of the project
if you include them in your abstract. We are all on the same team! This means that
you may use your colleagues' descriptions of significant enclosures in your abstract
without the use of quotation marks.
9.2.3. Abstract style guide and edicts
These are resolutions determined by the Despatches team in 2020.
Write out Colonial Office (instead of CO) or any abbreviations that are not easily
understood.
Write out first instance of words commonly abbreviated (examples: British Columbia
and Vancouver Island) and use abbreviations thereafter.
Try to work against the compulsion to make a case or argument in the abstracts: these
are summaries, not analytical papers. Do not editorialize. (Historians on the team
can let go of the compulsion to show-off every cool quote they found. It’s the readers
job to find the quotes.)
Avoid verbs that *read into* what you see as the motivation for the document. Tell
it like it is, not what you think it to be. If you're using a verb that puts you in
the writer's head, then you're off track from a summary and on track for a novel.
We cannot know what is in another person's mind. Here's a short list of “neutral” versb:
relates
conveys
notes
describes
Also see Janelle's list of Critical Verbs for some other suggestions.
Related to above we have placed a moratorium on the verb “writes,” because, like,
duh. Typically, Colonial Officials and people contacting the office do the following:
acknowledge
confirm
instruct
request
report
explain
relate
refer
transmits
*Note: We do not quote these “verbs” unless they are germane to the intention of the letter in some special way. You may
use quotes in cases where the verb is either uncommon or totally badass in terms of
interest to modern readers.
We are begrudgingly okay with using “minutes” as a verb, or a noun, in order to avoid the wordy and repetitive and lengthy clause
of “In the minutes…,” but we need to show the reader the content's origins, in the artifact sense. For
example, “Blackwood minutes that Douglas's canoe trip was necessary,” or “Blackwood's minute to Carnarvon reports that Douglas has received funds for supplies.” Some Colonial Office common action scenarios:
Recommendations: Blackwood's minute recommends…, or, Blackwood minutes to Carnarvon
that he recommends...
Authorizations: Blackwood's minute authorizes…
Confirmations: Blackwood's minute confirms…
We no longer feel the need to always mention recipients in the opening of the abstract
because senders and receivers appear in the header metadata. Mention recipients only
in cases where disambiguation is required.
9.2.4. Reviewing the process
If you feel bogged down by the above details and expectations, remember that the abstract
is supposed to provide a helpful summary of the correspondence, and so your overall
aim is to do the following:
Summarize the salient points of the original correspondence.
Mention any minutes particularly relevant to the original correspondence.
Mention any enclosures or attachments that provide further context to the original
correspondence or the document’s significance to the history of BC.
Last step, please record that you have commited a marked up version of the abstract
in XML in our ColDesp Abstract Project Tracker. Find the id of the despatch you added the abstract to and fill out the "in XML (NEW)"
cell with "Yes" and "(Your Initials)":
Note that most of the new abstracts won't have an entry in the "OLD" column, which
is to be expected. Phase 2 will be to update the old ones, time and resources permitting.
In your Google doc, you can also, add a token, "PUBLISHED" to your Google doc entry
= [PUBLISHED date-of-entry(ISO)].
9.2.5. Examples
Examples from a range of abstracts:
1. Simple correspondence, no minutes or enclosures: B64006 V667703
2. Simple correspondence with mentions of minutes/attachments: B67013CO V645FO02
3. Complex (long) correspondence with mentions of minutes/attachments B67013 B67022
9.3. Tagging abstracts
Below is an example of a tagged abstract, and where it should be placed within the
<teiHeader>.
<encodingDesc><styleDefDecl scheme="css"/></encodingDesc><profileDesc><abstract><p>On behalf of <name key="russell_j">Lord Russell</name>, <name key="layard">Layard</name> forwards to the Under-Secretary of State a letter from the Belgian Minister at <name type="place" key="london">London</name> in which the minister enquires about the “fate” of <name key="noiset">Noiset</name> who was last heard from while living in <name type="place" key="victoria">Victoria</name>. <name key="elliot_tf">Elliot</name>’s minute authorises <name key="blackwood_aj">Blackwood</name> to forward the inquiry to the Governor of <name type="place"
key="vancouver_island">Vancouver Island</name> and to inform the <orgName key="foreign_office">Foreign Office</orgName>.</p></abstract></profileDesc><revisionDesc><change resp="lyallg" when="2020-03-16">Added abstract.</change><change resp="lyallg" when="2019-04-10">Inserted revisionDesc.</change></revisionDesc>
In the example above, there are few things to pay close attention to:
Always add your netlink id or equivalent identification to an resp in a <change> tag within the <revisionDesc> with a date and a text value of "Added abstract."
The abstract is placed inside the <profileDesc> tag. If that tag doesn’t exist, you’ll have to create it. It appears after the <encodingDesc> tag within the <teiHeader> tag.
Tag the abstract's content just as you would the correspondence. That is, be sure
to tag people, places, and vessels in the abstracts (as long as the instance of each
already exists in our database), as well as dates. See the mark-up guides for people, places, vessels, organizations, and dates, for details and tips.
IMPORTANT: once you’ve committed your abstract to the database, make sure to go online to proofread
your work, and ensure that all links work as they should.
Some documents in the collection appear as both letterbook copies and originals. For
example, V597067 is the letterbook version of B597067. Notice that the letterbook version is written on lined paper and often contains
abbreviations (like "B.C.") as opposed to the original, which is not on lined paper
and has words typically spelled out in full. In these cases, add abstracts to the original versions, only. Also, write a statement in the abstract, as a separate paragraph, to indicate that
this is a letterbook copy, and point to the original despatch with a <ref> tag:
<div type="despatch_from_london"><p>This document is a letterbook copy of <ref target="cdc:B597067">B597067</ref>.
<!--Please note that the original was marked initially as part of the Vancouver Island
collection, and changed thereafter, presumably after receipt, to the British Columbia
collection.--></p></div>
Correspondingly, add a statement in the abstract of the original document:
<div type="despatch_from_london"><!--<note xml:id="B597067_1">Please note that this document exists as a <ref target="cdc:V597067">letterbook
copy</ref>.</note>--><p>See <ref target="cdc:V597067">V597067</ref> for a letterbook copy of this document.</p></div>
*Note: be on the lookout for any instances of originals or letterbook copies that
do not point to each other in their respective abstracts. As ever, if you are unsure
about any of this, please consult your Despatches colleagues.
9.4.2. Adding descriptions to enclosures and other files as needed
In addition to the designation mentioned above, Jim's team also summarized the content
within most of the enclosures, and other files. However, some enclosure or other-
file summaries may contain merely an author, an addressee, and a date. For example,
“Douglas to Lytton, 1 March, 1848.” In these cases, we review the image scans of the
document in question and summarize it ourselves below your Google doc abstract. Make
a note “SUMMARY NEEDED” above your new summary so that it is easily identified or
found by other Despatches team members if necessary. We then add our summary to the
XML file, as part of the existing list of enclosure or other-file descriptions. Add this new content to the original summary from Jim's team. This means adding content at the bottom of the XML file as well as in your abstract
and marking both up. Note that we will also need to go back and fix earlier abstracts
and other file entries that have not added content and mark-up.
10. People
The biographies appear in pop-up windows in a given despatch. Their purpose is to
enrich readers' sense of a given despatch by providing historical context.
In general terms, the biographies need a lot of work. It would be a project in itself
to finish them all. As of this writing, nearly 1,500 have no content, and nearly 250
need more revision or content.
We also inherited some biographies, mostly for 1858 from Jim’s team back in the 80s.
These bios don’t conform to our footnote style, and so at some point we’ll have to
dive in and edit them. See the “Edits to inherited biographies” section below.
10.1. Writing biographies
Our biographies try to present a given historical figure in the context of their role
as described in the despatches. The following list provides general expectations for
a given biographical entry:
Information relevant to the colonies of Vancouver Island and British Columbia is of
primary importance and should be presented first.
Frame the person within their role as mentioned in the despatches.
Birthplace and death (in the xml file, insert information inside ‘birth when’ and ‘death when’ tags at the top of each bio).
And, should the information be available…
Some personal background
Some educational background
Some professional background
A choice tidbit, should one emerge
In the absence of other source material, use the despatches. For example, in a recent entry for Shahoowha, for whom we could find nothing else,
we wrote the following: ‘Shahoowha was a Chief of the Nisga’a people. His name appears in the despatches as
one of the Nisga’a Chiefs who signed an agreement “to deliver the property taken from the Schooner “Nonpareil” in October 1861.” The agreement was made in response to “a robbery of goods…by the Nishka Indians, at Nass River.” The conflict was reported to be fuelled by “Drunkenness” however, the Nisga’a stated that “the master’s account of the goods taken [was] much exaggerated.”’
10.1.1. Content, structure, and voice
There’s no definite prescription here, except to try and keep it concise and relevant.
Two to three paragraphs, or roughly 250 words, is a good length. If you have a compelling
narrative, who could blame you if you go over the word count? But make sure you keep
it lively. The bio will appear in a pop-up box, so consider what length seems appropriate,
and what you would be willing to scroll through if you were on the site. The intended
audience is secondary and post-secondary readers and scholars. That said, try and
have some fun with it. After all, would you want to read a boring biography? Please
read the Style Guide section before you write anything.
When possible, information relevant to Vancouver Island and British Columbia should
appear within the first couple of paragraphs. Remember, it’s important to frame the
person within their role as it appears in the despatches. Try to include some personal,
educational, and professional background information. Balance hard facts with interesting
tidbits, or quotes, that illuminate the person’s character or experience.
To keep track of your sources as you draft, note your citations at the end of each
sentence in brackets (1). Alternatively, you can use the footnote function in Google
Docs and then add the brackets once you’re finished the editing phase so that footnote
numbers translate easily to the XML document. At the coding phase, you’ll need to
create a list of your sources in a separate paragraph. This process is covered in
the Tagging People and Biographies section.
10.1.2. Biography research
The Colonial Despatches website aims to be an academic resource, so please use academic sources for your
research, particularly on the web. Wikipedia is a fine starting point, but if you’re
unable to find that information in another verified source then we can’t use it. In
these instances, you can make a note within the biography XML file that links to the
webpage. This way, future researchers will know what, if anything, has been done for
this bio, and will have a place to start.
When you begin your research it’s best to check the XML file for any notes that were
left. To find these notes, go into the appropriate file where your figure’s biography
template is located. Any notes will be commented out in a <note> tag like in the example below:
<person xml:id="wade_j"><!-- IC, 2019-01-14 --><persName type="unavailable"><surname>Wade</surname>, <forename>John</forename></persName><!--<birth when="1111-11-11"></birth>--><!--<death when="1111-11-11"></death>--><!--<note>Private tutor of G. M. Sproat</note>--></person>
See Research Resources for a list of frequently used sources. To verify names, you can check the lists of
ship passengers from local newspapers in port cities. If you find yourself stuck,
please consult other members of the Despatches team. There are many e-books available online, particularly when researching people
with peerage titles; most e-books are considered a valid resource, but if you have
questions, please consult your colleagues.
Additionally, there are great subject guides for Victoria and Vancouver Island from the UVic libraries. A good book to consult, particularly in dealing with people
and place names, is Captain John T. Walbran’s British Columbia Coast Names. We keep a copy in the office, and it’s available in the library, call number: FC3806
W35 1971a.
IMPORTANT! If you are unable to find any outside information, please construct a short biography
based on the information available in the correspondence. After all, something is better than nothing, and we can always add more content later,
should a reliable source for a given name suddenly appear.
10.1.3. Example bios and a bit about them
These examples are meant to give you a taste of the “biodiversity” we currently have. Don’t get hung up on trying to recreate them!
See Grant, Captain Walter Colquhoun (1822-1861) for a long bio that summarizes well from a single, external source: the
Oxford DNB. This one also uses the despatch references well.
See Gough, Lieutenant General Lord Viscount Hugh (1779-1869) for another long-form bio.
See Adams, John R. for a bio that is, arguably, around the ideal length, and it opens with content immediately
relevant to the Despatches collection.
See Alcalá-Galiano, Officer Dionisio (1762-1805) for a long bio written on a rather well-known historical figure. This
bio uses multiple sources, both book and digital.
10.1.4. Edits to inherited biographies
Many of the inherited biographies require heavy editing, particularly in the B58_bios.xml
file. For a start, please apply our style to citations, spelling, and numbers (see
the Style Guide section). Please update language where needed, especially terms for Indigenous Peoples.
If possible, do some research to determine the particular Indigenous person or group
mentioned, and please consult supervising members of the Despatches team when you encounter questionable markers of Indigeneity.
Some of these bios are rambling behemoths, so please prune, trim, and reorder them
so they’re more concise and relevant to the despatches. Also, be sure to keep an eye
out for missing or misplaced tags for people, places, and vessels. Once the critical
changes are complete, check if the names in B58_bios.xml need to be placed in the
file for a different year.
10.2. XML mark-up for bios: getting started and workflow
10.2.1. Finding a person
First find your person by searching for the xml:id of the person in the xml/bios folder by right-clicking on bios and doing a search/replace
on the directory. For example, if we wanted to find Joseph Cahill we would do a search
for "cahill_j" in all lower-case with Case sensitive toggled on.
Finding Joseph Cahill
10.2.2. Adding birth and death dates
Now that we have found the person you can uncomment the birth and death elements by
hitting “'Ctrl'+'Shift'+','” and add the dates. (For Mac users it is: Cmd + shift + M)
<birth> and <death> elements commented out.<birth> and <death> elements have been uncommented with dates filled in.
A couple notes: (1) if you only know a year or a year and month, that is fine, just
add that information and delete the zeros for the day; (2) if you don't have a birth
or death date just leave the element commented out.
10.2.3. Adding bio content
Add your bio content by copy and pasting it into <p> elements in the <note> element. Every paragraph goes in its own <p>.
Content added to bio
10.2.4. Adding end notes
Now add your endnotes. In another <p> tag create a <listBibl> element and within that element add your first <bibl> entry with the number "1." which is your first note. Then add a xml:id to the <bibl> using the formula outlined in 7.2. Notation Numbers. For how to mark-up your citation see 7.3. Basic Endnotes.
One tip: you can copy and paste all the code from the examples and replace the values
with your own information, author, title, url, etc.
Added endnotes with xml:id. Examples are of an online dictionary and a book citation.
10.2.5. Linking endnote indicators with their corresponding note
To link your indicators with their note we will replace the current indicators (in
parenthesis if you formatted them as they are formatted in this example) with this
code:
<bibl corresp="#xml:id_b_corresponding number here"><hi style="vertical-align: super; font-size: 80%;">number goes here</hi></bibl>⚓
Copy and paste this code replacing your first indicator “(1)”. In the corresp, after the “#” add the xml:id of your first endnote and replace the text “number goes here” with the number of the note. Repeat this step until all your indicators are replaced
with a fully marked-up number.
Original plain text indicators to be replaced.Indicators with full mark-up including corresp linking to the endnote.
Note: do not tag the person whose bio you are writing. This is unnecessary.
10.2.7. Recursive tagging
This issue, depending on the pop-up in question, is a both a style and coding concern.
As a general rule, do not tag references to the entry you are already reading. This is true for bios, places, and vessel entries.
For example, in James Douglas’s bio, you need not tag the name “James Douglas,” as this would be recursive—in other words, refer back to the referent—and redundant,
as you’re already reading about James Douglas to start with.
Do tag all other references as you would in a despatch. For example, if Douglas's bio
refers to Lord Grey, then tag Lord Grey accordingly, as this is an entry external
to the Douglas bio.
10.2.8. Final steps
Finally, erase the type="unavailable" or type="incomplete". And add your initials in a comment with a date indicating that you
wrote the bio (credit for your work!).
Pointing to type="unavailable.type="unavailable is erased and writing credit comment added.
Make sure you check that your document is valid, save it, and commit it on the svn
repo.
10.3. Tagging people and biographies
10.3.1. Tagging people in the correspondence
This section deals with how to tag mentions of people in the letters. This task breaks
down into two parts: (1) tagging people already in the database, and (2) adding new
names to the database. This section assumes that you are already familiar with the
basics of tagging. If not, then consult a Despatches colleague.
10.3.1.1. Tagging people already in the database
What we mean by “already in the database” is that the name for the person in question has already been added to the biographies
files, and that the name can be found on the website. You can find all the names ever
added for all years on the biographies index page.
10.3.1.2. Steps to tagging names (for newbies)
Confirm that the name you need to tag is already in the database by going to the biographies index page.
Once you have confirmed that the name is already in the database, you will need to
know the person’s key value, or unique ID. In the following example, the unique ID
is in quotation marks: <name key="grey_hg">
To find a person’s unique ID on the biographies index page hover your mouse over the
name and a pop-up will reveal the unique ID, like magic!
Back in your XML document, it’s time to tag the name.
Highlight/select the name
On the keyboard, hit Ctrl + e and a pop-up will appear
Type ‘name’ (without quotes) into the pop-up, then click the ‘OK’ button. This will wrap your name in an open and closed name tag. NOTE: as soon as
you type ‘n’ the autocomplete options will appear, and you can select ‘name.’ At this point, you should have something that looks like this example:
<name>Earl Grey</name>
Add the key="" attribute after the open <name> tag, as in the following example:
<name key="XML_ID_here">Earl Grey</name>
Add your unique Id for the name between the quotes in the key="" attribute, as in the following example:
<name key="grey_hg">Earl Grey</name>
All done! You now have a fully tagged name.
10.3.1.3. Name tagging practices
When you tag names in the correspondence, never add space between the tags and the
name. For example:
Wrong: <name key="grey_hg"> Earl Grey</name>
Wrong: <name key="grey_hg">Earl Grey </name>
Right:<name key="grey_hg">Earl Grey</name>
Tag the name only, even in the case of possessives. For example, in the case of ‘Earl Grey’s letters,’ the tag would wrap around only ‘Earl Grey,’ as in <name key="grey_hg">Earl Grey</name>'s letter.
Tag ‘Mr.’ and its variants if it’s part of the name, as in <name key="blackwood_aj">Mr. Blackwood</name>.
DO NOT tag ‘Esquire’ and its variants, such as Esq., Eq., Esque., and so on.
DO NOT tag names in notes, footnotes, bibliographic information, or any other content clearly
separate from the correspondence. Also, do not tag the name of the person whose bio you’re marking up. Ask your Despatches colleagues if you’re uncertain about whom to tag.
You can wrap a name tag on titles, but only in cases where clarity is required. Otherwise,
do not tag them. For example, a paragraph might refer to Blanshard and Douglas, who
were both governors, and say something like, ‘Blanshard and Douglas both liked crumpets for breakfast.’ But, ‘the governor born in the Caribbean preferred his with jam.’ This is obviously a very rare scenario, but in this case we would tag ‘the governor’ as Douglas in this case, for purposes of disambiguation. But, when in doubt, leave
it out, or consult your Despatches colleagues as needed.
10.3.1.4. Adding new names to the database
This section presumes that you have access to the biography XML files, and that you
already know how to tag names.
IMPORTANT: Before you add new person to the biography files, make sure that they don’t already
exists in the database! Not sure? Check the the biographies index page.
As a rule, we always tag/add people mentioned in the correspondence. That is, names
that occur in the text of the transcribed correspondence. Of course, there may be
other names tucked into the non-transcribed enclosures, letters, and other files,
but we have neither the time nor resources to investigate them further.
The biography files are located in the “bios” folder (files path …/xml/bios). You’ll notice that there are multiple bios files,
with file names such as V46_bios.xml and V60_bios.xml. The “V” in the filename stands for Vancouver Island colony, and the number represents the
year. We break the bios files into separate years for two reasons: (1) if all the
names were in one, huge XML file, it would take too long to load, and (2) we can have
several people work on several different files at once without running into file version
conflicts.
Open the appropriate biography file in Oxygen.
NOTE: we add the person to the file for the year in which the person was first mentioned.
For example, Captain Duntze appears in letters spanning several years, but he’s mentioned
first in an 1846 letter, so his entry appears in the 1846 bios (V46_bios.xml).
If there isn't already an alphabetized section (based on the first letter of the surname)
then you need to add one. Let’s pretend that the new name is Peter Parker. First,
we add a comment tag, as this is a handy separator: <!-- PPPPPPPPPPPPP -->. Below the tag, we add a <personGroup> tag with the appropriate value: <personGrp xml:id="P"/>. Here’s an example of what it actually looks like in Oxygen:
<!-- PPPPPPPPPPPPP --><personGrp xml:id="P"/>
Choose an appropriate xml:id for your new person. In the example below, the unique ID, or name value, is in quotation
marks:
<person xml:id="duntze_ja"/>
NOTE: Choose a unique ID of the shortest possible length based on the last name of the
person. For example, let’s say you have someone name Constantine Rutherford Gonzoplix.
Chances are there is no other person named Constantine Rutherford Gonzoplix, at least
in this dimension, so you’re safe to create a unique ID from the last name only, as
in <person xml:id="gonzoplix">. However, if you find yet another ‘Smith,’ then you will likely need to incorporate the initials into the unique ID, as in <person xml:id="smith_jp">. As always, if you’re unsure about any of this, consult your Despatches colleagues.
Add a comment tag, with your initials and the date, so we know who wrote the entry,
and when. Add your comment tag after before the <persName> tag, as in this example:
We have a shortcut key to create a new bio placeholder. Press Ctrl Alt 1 (on Linux
or Windows OS). Below is an example of a bio template. Note that this is a placeholder
bio, one to which we have yet to add content the cursor will sit waiting for a new
unique xml:id:
The name tags must be entered in the following order: <surname>, <roleName> (if applicable; see below), then any <forename> tags. Always place commas directly after the closed </surname> tag, and in no other place. If you have only a surname, then don’t add a comma.
On <roleName> tags, the TEI writes the following: ‘<roleName> contains a name component which indicates that the referent has a particular role
or position in society, such as an official title or rank.’ Here’s an example:
Some <roleName> examples include Governor, Lieutenant, Sir, Lord, Earl, Justice, Reverend. With this
in mind, ‘Mr.’ is not considered a role, as such, nor is ‘Mrs.’ If the person in question has no ‘role’ as defined above, then do not add the <roleName> tag to the entry.
type=incomplete,complete, and unavailable bios are attributes that are added to indicate the state of a biography’s completeness.
When a biography is incomplete, we need to track this for statistics purposes, and
for easy searching. The attribute is added to the <persName> tag.
incomplete is used when content exists, but it’s unfinished or inadequate, and will be rewritten
in future:
<persName type="incomplete"/>
unavailable is used when no content has been written yet:
<persName type="unavailable"/>
When a biography is complete, neither of the above attributes should appear.
<birth> and <death> tags are commented out until we know either or both, as in the following example:
Once you know the date(s), fill in the year/month/day (or just year/month, or simply
year) and remove the comment tag(s). <birth> and <death> tags with certainty, or cert attribute, are used to alert the read that we aren’t entirely certain that we have
an accurate birth or death date. You have three value options with a cert attribute. Here’s what it looks like in code form:
These instructions assume that you have already read several placeographies, and that
you have at least a passing interest in the subject!
As with biographies and vessel entries, website readers can click on a place’s name
to learn about it. Places appear as mentioned in the letters, but readers can view
all the placeographies as a collection on the places index page.
The following is a working list of things to consider for your placeographies:
Keep it brief, aim for roughly 200 words.
In the first sentence, provide the relative location of the place, as in the following
examples:
American Bar is located along the Fraser River’s eastern bank, roughly 6 km above
Hope.
Cape Mudge is located on the south end of Quadra Island, which lies off the eastern
coast of Vancouver Island.
The Stikine River flows southwest out of Stikine Plateau through Northern BC and the
BC-Alaska boundary.
Provide the origin for the place’s name.
When possible, provide the Indigenous name and name origin.
TIP: Most First Nations groups have websites these days. Be sure to check these in order
to get the latest spellings.
We honour special characters for Indigenous and First Nations names. For example,
we write Hawaiʻi with the ʻokina, not an apostrophe.
Provide a given place’s historical significance, ideally with respect to local history.
Feel free to incorporate quotes or information about a given place from the Despatches collection.
Add any fun or significant facts you can find. If you’re not sure about whether or
not to include something, consult your Despatches colleagues.
If you need the unique ID of a given vessel (the “key=” value) refer to the places index page. Hover your mouse over a given place’s name and its key value will appear. The same
is true for people and vessels.
11.2.2. How to add a new place to the database
This process is, more or less, the same for adding newly discovered people to the
database. See the Adding new names to the database section for details. Note that unlike the biographies, which have separate files
for each year, the places are all in one big file!
11.3. Placeholder template for new places
Note that this is a placeholder only, one to which we have yet to add content. The
short-cut key for this template is Ctrl Alt 3.
IMPORTANT:“Un-comment” things later as you add the necessary content, specifically the <location> tags and the <desc> tags that contain your content and bibliographic information, respectively.
NOTE: As ever, if you're unsure as to what a complete placeography looks like, go to the
places file ([…]/xml/places/places.xml) and look at a completed entry!
11.3.1. How to tag placeographies in the places.xml file
We store and place new entries in an XML file called “places.xml.” The following is an example of a completed entry in XML format:
<place xml:id="birch_bay"><placeName>Birch Bay</placeName><location><geo>48.895159 -122.789767, 48.894745 -122.784574, 48.897412 -122.778117, 48.900577 -122.774573,
48.903075 -122.771535, 48.905907 -122.767357, 48.906740 -122.763684, 48.907573 -122.758871,
48.909905 -122.752664, 48.914401 -122.748231, 48.918730 -122.745824, 48.923976 -122.745444,
48.929887 -122.745950, 48.933801 -122.748865, 48.936798 -122.752541, 48.940711 -122.761161,
48.942541 -122.769655, 48.931378 -122.787392, 48.931710 -122.791955, 48.894492 -122.793313,
48.895159 -122.789767</geo></location><desc>Birch Bay is located just south of the Canada-US border in southeastern <name type="place" key="georgia_strait">Georgia Strait</name>. To the west, across the Strait from the bay, sits the southern <name type="place" key="gulf_islands">Gulf Islands</name>. In 1792, <name key="vancouver_g">Vancouver</name> anchored in the bay, and was inspired to name it in reference to the abundant birch
on the bay’s shores; the Spanish knew it as Ensenda de Garzon.<bibl><hi style="vertical-align: super; font-size: 80%;">1</hi></bibl></desc><desc>According to George Davidson, a British painter on <name key="vancouver_g">Vancouver</name>’s expedition, one of the Indigenous names for the bay was, in Davidson’s Anglicization,
“Tsan-wuch."<bibl><hi style="vertical-align: super; font-size: 80%;">2</hi></bibl></desc><!-- <name type="place" key="birch_bay">Birch Bay</name> --><desc><listBibl><bibl>1. Lynn Middleton, <title level="m">Placenames of the Pacific Northwest Coast</title> (Victoria: Elldee Publishing Company, 1969), 23.</bibl><bibl>2. Ibid.</bibl></listBibl></desc></place>
Note that between the <place></place> tag (the tag that contains the whole entry) <p> tags are invalid. So, we use a <desc> (description) tag instead. If you want multiple paragraphs then use multiple <desc> tags.
11.3.2. How to add <location>/<geo> tags
Each placeography should include a map link. This link takes readers to the Google
Maps location for a given place.
We have to add geo coordinates manually, see How to acquire coordinates for instructions. Geo coordinates are literally the longitude and latitude values
for a given point, or waypoint, in decimal degrees.
The <location> tag, which contains the <geo> tag, is placed after the closed </placeName> tag, as in the following example:
<place xml:id="birch_bay"><placeName>Birch Bay</placeName><location><geo>48.895159,-122.789767 48.894745,-122.784574</geo></location><desc>Birch Bay is located […]</desc></place>
The location appears inside a <geo> tag, and consists of one or more coordinates in lat,long format. Each lat,long pair
is delimited by a comma (with no space), and each pair is delimited by a space.
11.3.2.1. How to acquire coordinates
We recommend using Greg Newton’s Mercator Vertexer tool to generate your coordinates. Choose the type of location you need to specify (line
or polygon), draw the shape, then copy/paste the coordinates into the <geo> tag.
11.3.2.2. Polygons
Use a polygon, or multiple coordinates, when you wish to draw a bounding box around
a given location, as in the following:
A political region, such as province or territory
Cities
Bays and harbours
Islands
Groupings of islands, as in the Gulf Islands
Here is an XML example of what a polygon looks like. It’s just multiple coordinate-pairs,
separated by spaces, which by default become polygons:
Below is an example of what a polygon looks like in the “Places” index. Note that it’s also acceptable to repeat the final coordinate in order to
clarify that this is a closed shape rather than a path.
11.3.2.3. Lines
Use lines for rivers, streams, and portages, or anything else that runs only point-to-point
and beware, you’ll end up with an odd-looking blob in Google Maps if you don’t read
this section carefully!
To make a line you need to override the code that automatically converts multiple
geo coordinates to polygons.
To perform the override, you need to add a type=path attribute to the <location> tag, as in the following example:
Below is an example of what a line looks like in the “Places” index:
11.3.3. How to map a location with the Mercator Vertexer tool
Make sure the place isn’t mapped yet. In the example below, taken from the place.xml
file, we can see that there are no geo coordinates within the <geo> tags, so the place isn’t mapped yet.
Determine what type of location you’re working with (e.g. city, province, river) and
decide accordingly whether to map it as a point, polygon, or line. Since Bristol is
a city in England, we’ll map it as a point.
Assuming you’re working on a computer with two monitors, locate Bristol in Google Maps on one monitor.
Open the Mercator Vertexer tool on the other monitor and locate Bristol. As of February 2019, the tool does not allow searches, even though there’s a search bar in the upper-left corner, so we
need to find Bristol manually. The Google Maps page on your first monitor will help
you locate Bristol on Vertexer. Tip: if you’re not familiar with Vertexer, click on the big question mark at the bottom-right
corner. A Help/Tutorial window will pop up that will walk you through the mapping
process.
In the upper-right corner of Vertexer, there’s a drawing panel with four tools: hand
cursor (allows you to move around the map), simple marker (for adding points), polygon
(for drawing polygons), and polyline (for drawing lines). Since we’ll map Bristol
as a point, we’ll use simple marker. To place Bristol on Vertexer, click on the simple
marker tool and then click on Bristol. A green marker will appear above the point
clicked, and there will be a single pair of lat,long coordinates in the selected feature
box.
Now you can add the coordinates to the entry in the place.xml file, which will create
a map link. Click on the coordinates in the ‘Selected Feature’ box and copy/paste them into the entry in the place.xml file within the <geo> tags. Remember to save your work.
Note: when you add the coordinates of a line to place.xml, remember to add the attribute
type=path to the <location> tag.
When drawing polygons, perfect precision is appreciated but not required. Consult
your Despatches colleagues if you have any questions
Remember mapping can be controversial. Some places included in the placeographies
have been entangled in historical and current territorial disputes. As of February
2019, the project prefers mapping places in accordance with their current locations
and boundaries.
Places identified as First Nation locations in Canada require particular caution.
In these cases, if we can find current ‘official’ maps created by the appropriate group, it’s a good idea to use their maps. If you
use a cartographic resource other than Google Maps, please indicate the source as
a comment in the place.xml file.
11.3.4. Rules for unique placeography IDs/values
This section assumes that you already know how to add “placeholder,” or content-free, entries to the places.xml file. If not, then consult your Despatches colleagues before you proceed.
This section discusses cases where a new-found place name consists of two or more
words. For example, “Beacon Hill”.
Here’s what we’ve done so far:
If a place name consists of two or more words, make sure you do not leave a space between words in the key value.
Always use the full name of the place in the value so that it’ll sort correctly on the website, though you
can also combine two names with an underscore.
<name type="place"
key="beaver_lake_settlement">Beaver Lake Settlement</name>
11.4. How to indicate incomplete place entries
When a place entry is empty or incomplete we need to track it for statistics purposes,
and for easy searching. To mark a place entry as incomplete, please add the attribute
type=unavailable, incomplete, or rudimentary to the <placeName> tag, as in the following examples:
<place xml:id="seleassa"><placeName type="unavailable">Archer</placeName><location>[...]</location><desc>Content not yet available.</desc><!-- XML code example: <name type="place" key="seleassa">Seleassa</name> --></place>
Note that we add the statement “content not yet available” to the content. Or, in cases where we have added a little bit of content, we handle
it as in the following example:
<place xml:id="statapoosten"><!-- KSS 2022-10-12: needs sources and more research --><placeName type="incomplete">Statapoosten</placeName><location>[...]</location><desc>In <date when="1859">1859</date>, the Northwest Boundary Survey established Statapoosten, or Statapoostin, as an astronomical
station slighty east of Gilpin. The map provided, above, covers two high points in
the area that they might have used.</desc><!-- <name type="place" key="statapoosten">Statapoosten</name> --></place>
Note that this place has no references, so it is clear that the research is not complete.
If some research has been done, and a basic entry has been written, but you believe
that more research would yield a more useful description, you can mark the entry as
rudimentary:
<place xml:id="port_staniforth"><!-- LCH 2015-01-28--><!-- KSS 2022-10-12: needs sources and more research --><placeName type="rudimentary">Port Staniforth</placeName><location>[...]</location><desc>At present, there is no known location for a Port Staniforth. However, there is a
a Staniforth Point in the area <name key="pike">Pike</name> refers to as Port Staniforth.</desc><desc><listBibl><bibl xml:id="port_staniforth_b_1">1. <title level="a"><ref type="external"
target="http://www4.rncan.gc.ca/search-place-names/unique/JCOPT">Staniforth Point</ref>,</title><title level="m">Natural Resources Canada</title>.</bibl></listBibl></desc><!-- <name type="place" key="port_staniforth">Port Staniforth</name> --></place>
Note that if you are linking to another Despatches document using the cdc: prefix,
you can add type=citation to the <ref> tag, and then the content of the <ref> element will be replaced by the full citation of the document during the build process.
This is a convenient way to provide a detailed and accurate citation without much
trouble.
12. Vessels
12.1. Writing vessel entries
These instructions assume that you’ve already read several vessel entries, and that
you have at least a passing interest in the subject!
As with biographies and “placeographies,” website readers can click on a vessel name to learn about it. Vessels appear as mentioned
in the letters, but readers can view all the vessels as a collection on the vessels index page.
The following is a working list of things to consider for your vessel entries:
Keep it brief--aim for roughly 200 words.
When possible, include date of launch and fate, that is date of decommission, when
it was dismantled, or sunk!
Pull in interesting content from the despatches, should the ship be mentioned in the
collection.
Mention who owned the boat.
Add any fun or significant facts you can find. If you’re not sure about whether or
not to include something, consult your Despatches colleagues.
See Research Resources section for a list of books and websites you can consult for source material.
12.1.1. Usage tips, with examples
The world of ships and vessels has all kinds of weights, measures, and technical details
to consider. See the CMOS 8.116 for more information. Here’s a working list of usage tips:
We write in metres and tonnes, not yards and tons. See the Preferred Spelling section for more information.
Even if your source material is presented in feet convert it to metres. And always
round your numbers. For example, a 235-foot ship is 71.628 metres in length, which
we would round up, in this case, to 72 metres.
As a general rule, ignore the tonnage of ships; it’s an editor/writer’s nightmare.
It can be difficult, especially when one deals with old sources, to determine whether
or not ‘tons’ refers to Builder’s Old Measurement [BOM or bm] or some other form of ‘tonnage,’ which measure capacity, not weight, and this is not to be confused with displacement tonnage. But, if you have to include it for the sake of disambiguation, then consider the
following. Even if your source material is presented in tons, convert it to (metric)
tonnes. Where ship weights are concerned, especially for British vessels, these would
be in long tonnes. This is all quite confusing to young minds, who grew up as metric-only
natives. Here’s a cheat sheet:
Tonne = 1000kg, nothing to do with old-timey weights. This is the tonne we use in Canadian
weights and writing.
British tonne, spelled the same way to confuse you, = 2,240 pounds. Almost certainly this is the
weight used for any 19th-century ships.
US ton = 2000 pounds. It’s the United States that refer to ‘metric tons,’ or 1000kg, when they want to distinguish it from their tons.
So, most Canadian-published books we use, such as Scott’s The Encyclopedia of Raincoast Place Names, already write in metres and tonnes. But, be on alert for US-published books that
write ‘tons’ in reference to ships, when they mean (long) tonnes! Arg.
We abbreviate ‘metres’ to ‘m.’ E.g. this steam-powered ship was 48 m long and 11 m wide. Note the space between
the numbers and the ‘m.’
As CMOS notes‘when such abbreviations as USS (United States ship) or HMS (Her [or His] Majesty’s
ship) precede a name, the word ship or other vessel type should not be used.’
Wrong: HMS ship Alarm.
Correct: HMS Alarm.
All ship names must be capitalized and italicized.
Do not italicize ‘HMS,’‘USS,’ or anything similar.
Wrong: HMS Alarm.
Correct: HMS Alarm.
Here’s an example of what a completed vessel entry looks like, as taken from the “indexes” page:
12.2. Tagging vessel entries
12.2.1. How to tag vessels that appear in the correspondence files
This one is pretty straightforward: wrap the correct tag around it.
<name type="vessel" key="topaze">Topaze</name>
If you need the unique ID of a given vessel, the “key=” value, refer to the vessels index page. Hover your mouse over a given vessel’s name and its key value will appear.
The same is true for people and places.
NOTE: In cases where you encounter HMS before a ship name, as in HMS Discovery, tag only “Discovery.” HMS is not part of the vessel name; furthermore, if you tag the HMS it will be rendered
in italics along with the ship name, which is counter to Chicago style (see CMOS 8.116).
12.2.2. How to add a new vessel to the database
This process is, more or less, the same for adding newly discovered people to the
database. See the Adding new names to the database section for details.
Note that unlike the biographies, which have separate files for each year, the vessels
are in two files: vessels.xml (which you will use almost exclusively) and the peripheral_vessels.xml
file (which you will use rarely). The latter file is for famous vessels that don’t
happen to appear in the collection, or vessels that we mention in our bios or placeographies.
Talk to your Despatches colleagues if you are unsure which file to use!
12.3. Placeholder template for new vessels
Note that this is a placeholder only, one to which we have yet to add content. The
short-cut key for this placeholder is Ctrl Alt 2.
<item xml:id="${caret}"><!-- Added by INITIALS; 0000-00-00 --><label><name type="vessel" key="KEY">VESSEL NAME</name></label><p/></item>
NOTE: As ever, if you're unsure as to what a complete vessel entry looks like, go to the
vessels file ([…]/xml/vessels/vessels.xml) and look at a completed entry!
12.3.1. How to tag vessel entries in the vessels.xml file
Let’s look at an example of a completed vessel entry from the vessels.xml file. This
example has all the typical components of a completed entry including all the usual
markup, ref links to despatches, and a complete set of footnotes with corresponding
superscript indicators.
<item xml:id="bacchante"><!-- KSS wrote 2013-10-24 --><label>HMS <name type="vessel" key="bacchante">Bacchante</name>, <date from="1859" to="1879">1859-1879</date></label><p>The HMS <name type="vessel" key="bacchante">Bacchante</name> was a screw-driven steam frigate with 51 guns and a complement of 560 sailors.<bibl><hi style="vertical-align: super; font-size: 80%;">1</hi></bibl></p><p>This large ship, at 72 m, frequented <name type="place" key="esquimalt">Esquimalt</name> in the <date from="1860" to="1869">1860</date>s under the command of Captain Donald Mackenzie and it served as flagship to <name key="maitland">Maitland</name>, commander-in-chief of the Pacific squadron from <date from="1860" to="1862">1860-62</date>.<bibl><hi style="vertical-align: super; font-size: 80%;">2</hi></bibl></p><p>The <name type="vessel" key="bacchante">Bacchante</name> was launched at <name type="place" key="portsmouth">Portsmouth</name> in <date when="1859">1859</date> and commissioned for service on the Pacific station on <date when="1860-04-18">18 April 1860</date>.<bibl><hi style="vertical-align: super; font-size: 80%;">3</hi></bibl> Its design, along with several other vessels, including the <name type="vessel" key="topaze">Topaze</name>, was based on the lines of the <name type="vessel">Shannon</name><!-- KSS note: not to be confused with "H.M. Mail Steam Packet 'Shannon'" as seen
in B636M02.xml --> (1855).<bibl><hi style="vertical-align: super; font-size: 80%;">4</hi></bibl></p><p><ref target="cdc:V627092">This correspondence</ref> from <name key="newcastle">Newcastle</name> to <name key="douglas_j">Douglas</name> notes the absence of guns at <name type="place" key="victoria">Victoria</name> and <name type="place" key="esquimalt">Esquimalt</name> and reports that <q>arrangements have been made for landing two 68 [pounder] Guns which may be spared
from H.M.S. <q><name type="vessel" key="bacchante">Bacchante</name></q> and <q><name type="vessel" key="topaze">Topaze</name></q>.</q></p><p><listBibl><bibl>1. Andrew Scott, <title level="m">The Encyclopedia of Raincoast Place Names</title> (Madeira Park, BC: Harbour Publishing, 2009), 54.</bibl><bibl>2. Ibid.</bibl><bibl>3. <title level="a"><ref type="external"
target="http://www.pbenyon.plus.com/18-1900/B/00435.html">Bacchante</ref>,</title><title level="m">Index of 19th Century Naval Vessels</title>.</bibl><bibl>4. William Laird Clowes, <title level="m">The Royal Navy: A History</title> (London: Sampson Low, Marston and Company, 1901), 6:199.</bibl></listBibl></p><!-- XML code example: <name type="vessel" key="bacchante">Bacchante</name> --></item>
12.3.2. Rules for unique vessel IDs/values
This section assumes that you already know how to add “placeholder,” or content-free, entries to the vessels.xml file. If not, then consult your Despatches colleagues before you proceed.
This section discusses cases where a new-found vessel’s name consists of two or more
words. For example, the Mary Dare.
Here’s what we’ve done, so far:
If a vessel name consists of two or more words, make sure you do not leave a space between words in the key value.
Always use the full name of the vessel in the value so that it will sort correctly on the website, though
you can also combine two names with an underscore.
<name type="vessel"
key="prince_of_the_seas">Prince of the Seas</name>
12.4. Vessels not in the Despatches
In some cases, you may mention a vessel that doesn’t appear in the despatches. For
example, in a biography pop-up about Captain Cook, we may mention HMS Discovery.
First, be certain that the ship isn’t mentioned in the despatch collection. To do
this, use the search feature in Oxygen where you can search all files and folders.
Once you’ve established the given vessel's absence from the despatch collection and
related files—that is, places.xml, vessels.xml, peripheral_vessels.xml, and all the
biography files—add your new vessel to the “peripheral_vessels.xml” file.
See the section above, Rules for unique Vessel IDs/values, for information on creating unique identifiers for vessels, otherwise, please consult
your Despatches colleagues on the process required to create a new vessel tag and
entry in the “peripheral_vessels.xml” file.
12.5. How to indicate incomplete vessel entries
When a vessel entry is incomplete we need to track it for statistics purposes, and
for easy searching. To mark a vessel entry as incomplete, please add the attribute
subtype=incomplete to the <name> tag, as in the following example:
<item xml:id="archer"><label><name subtype="incomplete" type="vessel"
key="archer">Archer</name></label><p>Content not yet available.</p><!-- XML code example: <name type="vessel" key="archer">Archer</name> --></item>
Note that we add the statement “content not yet available” to the content. Or, in cases where we have added a little bit of content, we handle
as in the example below:
<p>According to <ref target="cdc:V605LN06">this document</ref>, this ship was an HBC party barge. Further content not yet available.</p>
13. Organizations
This section describes the addition of organization entries to the orgography and
tagging entities. Organizations are entities like government departments, religious
groups and private corporations.
13.1. Adding an organization to the index
The orgography is located at orgs/organizations.xml. It is organized by type and then alphabetically. The current org types are:
Miscellaneous
Governmental Institution
Religious Affiliation
Private Corporation
Legal Organization
A standard organization entry looks like this:
<org xml:id="emigration_office"
type="governmental"><orgName>Emigration Office</orgName><desc>The Colonial Land and Emigration Commission was established in <date when="1840">1840</date>. A board of commissioners was appointed to manage the sales of Crown lands in British
colonies and regulate emigration from the UK to the colonies. The commissioners had
the power to use the proceeds from land sales to defray the expense of emigration.
They corresponded with colonial governors indirectly through the Colonial Secretary
(head of the Colonial Office). They also supervised the emigration officers stationed
in British colonies. The first board rented a private house for their office space
on Park Street, Westminster, <name type="place" key="london">London</name>.<bibl corresp="#eo_b_1"><hi style="vertical-align: super; font-size: 80%;">1</hi></bibl></desc><desc>It became Emigration Commission in <date when="1856">1856</date> after the imperial government had granted the rights of administering Crown lands
to the colonial governments.<bibl corresp="#eo_b_2"><hi style="vertical-align: super; font-size: 80%;">2</hi></bibl> In <date when="1878">1878</date>, the Commission was replaced with Emigration Department set up in the <orgName key="co">Colonial Office</orgName>.<bibl corresp="#eo_b_3"><hi style="vertical-align: super; font-size: 80%;">3</hi></bibl></desc><desc><listBibl><bibl xml:id="eo_b_1">1. Fred H. Hitchins, <title level="m">The Colonial Land and Emigration Commission</title>, (Pennsylvania: University of Pennsylvania Press, 1931), 42-45, 59, 159.</bibl><bibl xml:id="eo_b_2">2. Ibid., 310.</bibl><bibl xml:id="eo_b_3">3. Ibid., 94.</bibl></listBibl></desc></org>
This example can be used as a template. Make sure to change the type on the <org> if necessary. Also tag other entities as required.
13.2. Tagging orgs
All organizations in our orgography should be tagged throughout the database. In the
despatches and the abstracts, organizations are tagged with an <orgName> and unique id in a key.
<orgName key="hbc">Hudson's Bay Company</orgName>
That's it! After all the people, place and vessel tagging this is no great challenge,
just remember that it is <orgName> and not <name> and you're good to go.
14. Miscellaneous notes
14.1. Document taxonomy
Eventually there will be document categories <catRef> elements to classify documents into types. [In progress 2019-02-14 LM]
14.2. Regular expressions for Oxygen
These are used in on Oxygen’s find/replace dialogue and can apply to individual files when you Ctrl+F in one
document, or on multiple files, when you select folders and right-click > Find/Replace
in files.
14.2.1. Lookahead and lookbehind
Use this search type to find phrases excluding certain words. For example, if you
want to find Hudson's Bay, but without “Company,”“House,”“Territory,” and so on:
Hudson's Bay (?![Cc]o)(?![Hh]ouse)(?![Tt]er)
Here’s another simpler way to achieve similar results:
Hudson's Bay [^CHch]
The above asks the search to catch “Hudson's Bay” but without words that contain “C” as in “Company” or “H” as in “House,” and the lower case of each. In this search, I wanted to find instances of “Hudson's Bay Territory” or “Hudson's Bay Territories,” and this trimmed the results to a manageable level.
14.2.2. Location independence
Use this template to find two instances on separate lines in the same file or document,
as long as the first term appears before the second in a given file:
(?=.*search term).*second search term
For example, let's say we wanted to find all the files that contained the word “Douglas” AND the word “coal”:
The example below is used to find instances where any number (the ‘\d’ part, ‘d’ = ‘digit’) is followed by (the ‘+’ part) the letter ‘m.’ I was looking for things such as 37m, 33m, 55m, and so on.
The example below moves all instances of ‘HMS’ outside of quotes. Note that ‘( )’ gets rid of spaces after ‘HMS’ to satisfy the schematron after it’s been replaced.
How many of these vessels are located in a <p> element?
//p/name[type='vessel']
Find all instances where Douglas sent a confidential letter to London in C0/60:
//idno[contains(type,'documentType')][contains(.,'Confidential') or contains(.,'Private')][ancestor::teiHeader/descendant::author[name='Douglas']][ancestor::teiHeader/descendant::idno[type='coNumber'][.='60']]
[Martin will fill this section in as of 2019-02-14 LM]
14.7. Snippets
Snippets of particularly interesting passages in the despatches are displayed at random
on the Despatches home page. You can click on the snippet and it will link you to the file. However,
it’s our job to find the passages. So, should you come across the a juicy tidbit that
you think worthy of notice, please ask tag it like this:
<p>[…]<seg type="snippet"
xml:id="V58002_snippet_1">this is a shocking or interesting fragment of text</seg>[…]</p>
Create a unique xml:id attribute for the snippet by concatenating the ancestor TEI element's xml:id (without the trailing .scx if there is one) with “_snippet_” and the number of that snippet in the document.
15. Research resources
There are hundreds of sources that have been used in the Despatches writing. The following resources are only meant as a starting point.
Should you find the author or publication suspect, please consult the Despatches team.
Captain John T. Walbran’s British Columbia Coast Names. We keep a copy in the office, and it’s available in the library, call number: FC3806
W35 1971a.
NOTE: THIS SECTION DOES NOT CONTAIN ACTUAL DOCUMENTATION.
Use this sectionfor test-encoding anything that you want to experiment with in the documentation. We
will eventually delete it.
<div><head>This is a heading.</head><p xml:lang="en">This is a paragraph.</p><!-- This is a comment. --></div>
This paragraph mentions the <pb> element, the facs attribute, and the value stuff.jpg. It also uses the <tag> element: <pb facs="stuff">. Because the <pb> element is in our Despatches schema, it is linked automatically to its specification,
but because the <tag> element is not in our schema, it isn't linked.
This paragraph talks about entity references, such as & for the ampersand (&),
and — for the em dash (—). You can see from these examples how to encode an
entity so that it shows the actual character, or it shows the entity reference. If
you wrap the latter in a <code> element, it will look better: &.
Appendix A
Appendix A.1 Elements
Appendix A.1.1 <TEI>
<TEI> (TEI document) contains a single TEI-conformant document, combining a single TEI header with one
or more members of the model.resource class. Multiple <TEI> elements may be combined within a <TEI> (or <teiCorpus>) element. [4. Default Text Structure15.1. Varieties of Composite Text]
This element is required. It is customary to specify the TEI namespace http://www.tei-c.org/ns/1.0 on it, for example: <TEI version="4.4.0" xml:lang="it" xmlns="http://www.tei-c.org/ns/1.0">.
Example
<TEI version="3.3.0" xmlns="http://www.tei-c.org/ns/1.0"><teiHeader><fileDesc><titleStmt><title>The shortest TEI Document Imaginable</title></titleStmt><publicationStmt><p>First published as part of TEI P2, this is the P5
version using a namespace.</p></publicationStmt><sourceDesc><p>No source: this is an original work.</p></sourceDesc></fileDesc></teiHeader><text><body><p>This is about the shortest TEI document imaginable.</p></body></text></TEI>
Example
<TEI version="2.9.1" xmlns="http://www.tei-c.org/ns/1.0"><teiHeader><fileDesc><titleStmt><title>A TEI Document containing four page images </title></titleStmt><publicationStmt><p>Unpublished demonstration file.</p></publicationStmt><sourceDesc><p>No source: this is an original work.</p></sourceDesc></fileDesc></teiHeader><facsimile><graphic url="page1.png"/><graphic url="page2.png"/><graphic url="page3.png"/><graphic url="page4.png"/></facsimile></TEI>
<ab> (anonymous block) contains any component-level unit of text, acting as a container for phrase or inter
level elements analogous to, but without the same constraints as, a paragraph. [16.3. Blocks, Segments, and Anchors]
The <ab> element may be used at the encoder's discretion to mark any component-level elements
in a text for which no other more specific appropriate markup is defined. Unlike paragraphs,
<ab> may nest and may use the type and subtype attributes.
Example
<div type="book" n="Genesis"><div type="chapter" n="1"><ab>In the beginning God created the heaven and the earth.</ab><ab>And the earth was without form, and void; and
darkness was upon the face of the deep. And the
spirit of God moved upon the face of the waters.</ab><ab>And God said, Let there be light: and there was light.</ab><!-- ...--></div></div>
Schematron
<sch:report test="(ancestor::tei:l or ancestor::tei:lg) and not( ancestor::tei:floatingText
|parent::tei:figure |parent::tei:note )"> Abstract model violation: Lines may not
contain higher-level divisions such as p or ab, unless ab is a child of figure or
note, or is a descendant of floatingText.
</sch:report>
This element is intended only for cases where no abstract is available in the original
source. Any abstract already present in the source document should be encoded as a
<div> within the <front>, as it should for a born-digital document.
Example
<profileDesc><abstract resp="#LB"><p>Good database design involves the acquisition and deployment of
skills which have a wider relevance to the educational process. From
a set of more or less instinctive rules of thumb a formal discipline
or "methodology" of database design has evolved. Applying that
methodology can be of great benefit to a very wide range of academic
subjects: it requires fundamental skills of abstraction and
generalisation and it provides a simple mechanism whereby complex
ideas and information structures can be represented and manipulated,
even without the use of a computer. </p></abstract></profileDesc>
<add> (addition) contains letters, words, or phrases inserted in the source text by an author, scribe,
or a previous annotator or corrector. [3.5.3. Additions, Deletions, and Omissions]
In a diplomatic edition attempting to represent an original source, the <add> element should not be used for additions to the current TEI electronic edition made
by editors or encoders. In these cases, either the <corr> or <supplied> element are recommended.
In a TEI edition of a historical text with previous editorial emendations in which
such additions or reconstructions are considered part of the source text, the use
of <add> may be appropriate, dependent on the editorial philosophy of the project.
Example
The story I am
going to relate is true as to its main facts, and as to the
consequences <add place="above">of these facts</add> from which
this tale takes its title.
Addresses may be encoded either as a sequence of lines, or using any sequence of component
elements from the model.addrPart class. Other non-postal forms of address, such as telephone numbers or email, should
not be included within an <address> element directly but may be wrapped within an <addrLine> if they form part of the printed address in some source text.
Example
<address><addrLine>Computing Center, MC 135</addrLine><addrLine>P.O. Box 6998</addrLine><addrLine>Chicago, IL</addrLine><addrLine>60680 USA</addrLine></address>
This element should be used for postal addresses only. Within it, the generic element
<addrLine> may be used as an alternative to any of the more specialized elements available from
the model.addrPart class, such as <street>, <postCode> etc.
Example
Using just the elements defined by the core module, an address could be represented
as follows:
<address><addrLine>Computing Center, MC 135</addrLine><addrLine>P.O. Box 6998</addrLine><addrLine>Chicago, IL 60680</addrLine><addrLine>USA</addrLine></address>
Example
<address><country key="FR"/><settlement type="city">Lyon</settlement><postCode>69002</postCode><district type="arrondissement">IIème</district><district type="quartier">Perrache</district><street><num>30</num>, Cours de Verdun</street></address>
This example shows an appInfo element documenting the fact that version 1.5 of the
Image Markup Tool1 application has an interest in two parts of a document which was
last saved on June 6 2006. The parts concerned are accessible at the URLs given as
target for the two <ptr> elements.
As an alternative to using the scheme attribute a namespace prefix may be used. Where both scheme and a prefix are used, the prefix takes precedence.
Example
<p>The TEI defines several <soCalled>global</soCalled> attributes; their names include
<att>xml:id</att>, <att>rend</att>, <att>xml:lang</att>, <att>n</att>, <att>xml:space</att>,
and <att>xml:base</att>; <att scheme="XX">type</att> is not amongst them.</p>
<author> (author) in a bibliographic reference, contains the name(s) of an author, personal or corporate,
of a work; for example in the same form as that provided by a recognized bibliographic
name authority. [3.12.2.2. Titles, Authors, and Editors2.2.1. The Title Statement]
Particularly where cataloguing is likely to be based on the content of the header,
it is advisable to use a generally recognized name authority file to supply the content
for this element. The attributes key or ref may also be used to reference canonical information about the author(s) intended
from any appropriate authority, such as a library catalogue or online resource.
In the case of a broadcast, use this element for the name of the company or network
responsible for making the broadcast.
Where an author is unknown or unspecified, this element may contain text such as Unknown or Anonymous. When the appropriate TEI modules are in use, it may also contain detailed tagging
of the names used for people, organizations or places, in particular where multiple
names are given.
Example
<author>British Broadcasting Corporation</author><author>La Fayette, Marie Madeleine Pioche de la Vergne, comtesse de (1634–1693)</author><author>Anonymous</author><author>Bill and Melinda Gates Foundation</author><author><persName>Beaumont, Francis</persName> and
<persName>John Fletcher</persName></author><author><orgName key="BBC">British Broadcasting
Corporation</orgName>: Radio 3 Network
</author>
Contains phrase-level elements, together with any combination of elements from the model.biblPart class
Example
<bibl>Blain, Clements and Grundy: Feminist Companion to Literature in English (Yale,
1990)</bibl>
Example
<bibl><title level="a">The Interesting story of the Children in the Wood</title>. In
<author>Victor E Neuberg</author>, <title>The Penny Histories</title>.
<publisher>OUP</publisher><date>1968</date>.
</bibl>
Example
<bibl type="article" subtype="book_chapter"
xml:id="carlin_2003"><author><name><surname>Carlin</surname>
(<forename>Claire</forename>)</name></author>,
<title level="a">The Staging of Impotence : France’s last
congrès</title> dans
<bibl type="monogr"><title level="m">Theatrum mundi : studies in honor of Ronald W.
Tobin</title>, éd.
<editor><name><forename>Claire</forename><surname>Carlin</surname></name></editor> et
<editor><name><forename>Kathleen</forename><surname>Wine</surname></name></editor>,
<pubPlace>Charlottesville, Va.</pubPlace>,
<publisher>Rookwood Press</publisher>,
<date when="2003">2003</date>.
</bibl></bibl>
<biblScope> (scope of bibliographic reference) defines the scope of a bibliographic reference, for example as a list of page numbers,
or a named subdivision of a larger work. [3.12.2.5. Scopes and Ranges in Bibliographic Citations]
When a single page is being cited, use the from and to attributes with an identical value. When no clear endpoint is provided, the from attribute may be used without to; for example a citation such as “p. 3ff” might be encoded <biblScope from="3">p. 3ff</biblScope>.
It is now considered good practice to supply this element as a sibling (rather than
a child) of <imprint>, since it supplies information which does not constitute part of the imprint.
<catDesc> (category description) describes some category within a taxonomy or text typology, either in the form of
a brief prose description or in terms of the situational parameters used by the TEI
formal <textDesc>. [2.3.7. The Classification Declaration]
(The original document sent by the writer and received by the addressee.)
cdt:cdtDraft
(The draft of a document (usually, but not always, subsequently transcribed, signed
and sent).)
cdt:cdtLetterbook
(The letterbook copy of a document kept by the author/sender.)
cdt:cdtCopy
(A (non-letterbook) copy of the document.)
cdt:cdtSchedule
(A schedule compiled by Colonial Office staff.)
cdt:cdtSentToLondon
(Documents sent to offices in London, such as the Colonial Office.)
cdt:cdtSentFromLondon
(Documents sent from offices in London, such as the Colonial Office.)
cdt:cdtSentToColony
(Documents sent to one of the colonies, normally to the colonial governor.)
cdt:cdtSentFromColony
(Documents sent from one of the colonies, normally by the colonial governor.)
cdt:cdtNumbered
(The document has a number of some kind, such as a Colonial Office registration number.
Many documents will have multiple numbers.)
cdt:cdtSeriesNumber
(The document has a series number, such as the numbering applied to despatches to and
from London.)
cdt:cdtCoNumber
(The document has a Colonial Office registration number (assigned on receipt in London).)
cdt:cdtBoardOfTrade
(The Board of Trade)
cdt:cdtColonialOffice
(The Colonial Office)
cdt:cdtForeignOffice
(The Foreign Office)
cdt:cdtLandBoard
(The Land Board)
cdt:cdtWarOffice
(The War Office)
cdt:cdtFinancial
(A document that discusses financial or economic issues.)
cdt:cdtLegal
(A document that discusses judicial or legislative issues.)
cdt:cdtEconomicActivity
(A document that discusses economic activity in the colonies.)
cdt:cdtFarming
(A document that discusses farming.)
cdt:cdtResources
(A document that discusses resources other than mining, coal, gold, and lumber.)
cdt:cdtMining
(A document that discusses mining.)
cdt:cdtCoal
(A document that discusses coal.)
cdt:cdtGold
(A document that discusses gold.)
cdt:cdtLumber
(A document that discusses lumber.)
cdt:cdtFishing
(A document that discusses fishing and fisheries.)
cdt:cdtHunting
(A document that hunting.)
cdt:cdtTaxation
(A document that discusses taxes and licences.)
cdt:cdtTrade
(A document that discusses trade.)
cdt:cdtImport
(A document that discusses trade imports.)
cdt:cdtExport
(A document that discusses trade exports.)
cdt:cdtInternalTrade
(A document that discusses internal trade (between colonies, between Indigenous groups
and peoples, or any combination of the two).)
cdt:cdtSecurity
(A document that discusses colonial security and issues related to the same.)
cdt:cdtPolicing
(A document that discusses policing.)
cdt:cdtArms
(A document that discusses arms, weapons, and ordnance.)
cdt:cdtMilitary
(A document that discusses military security, deployment, or protection.)
cdt:cdtNavy
(A document that discusses the navy.)
cdt:cdtArmy
(A document that discusses the army.)
cdt:cdtInfrastructure
(A document that discusses the creation of infrastructure, such as buildings, roads,
bridges, etc., in the colonies.)
cdt:cdtBuildings
(A document that discusses the construction and maintenance of buildings.)
cdt:cdtBridges
(A document that discusses poltical relations with the United States.)
cdt:cdtRoads
(A document that discusses poltical relations with Spain.)
cdt:cdtPublicWorks
(A document that discusses poltical relations with Indigenous groups and peoples.)
cdt:cdtMarine
(A document that discusses poltical relations with Great Britain.)
cdt:cdtRail
(A document that discusses poltical relations with the Hudson's Bay Company.)
cdt:cdtCommunications
(A document that discusses poltical relations with the Hudson's Bay Company.)
cdt:cdtTelegraph
cdt:cdtMail
cdt:cdtInternationalRelations
(A document that discusses relations between one or both colonies and other geopolitical
entities, groups, organizations, and peoples.)
cdt:cdtRussia
(A document that discusses poltical relations with Russia.)
cdt:cdtUnitedStates
(A document that discusses poltical relations with the United States.)
cdt:cdtSpain
(A document that discusses poltical relations with Spain.)
cdt:cdtIndigenous
(A document that discusses poltical relations with Indigenous groups and peoples.)
cdt:cdtGreatBritain
(A document that discusses poltical relations with Great Britain.)
cdt:cdtHudonsBayCompany
(A document that discusses poltical relations with the Hudson's Bay Company.)
cdt:cdtPersonal
(A personal letter (often a solicitation for an appointment or posting).)
cdt:cdtPrivate
(A private document, normally marked as such in the header.)
cdt:cdtSeparate
(A separate document, normally marked as such in the header.)
cdt:cdtAccounting
(The document contains financial information in some structured format, such as a table
of expenditures.)
cdt:cdtMinutes
(The document contains or consists of minutes (usually written by Colonial Office staff).)
cdt:cdtMarginalia
(The document contains marginal annotations of some kind.)
cdt:cdtMap
(The document is a map, or has a map drawn on one of its pages.)
cdt:cdtEnclosures
(The document contains enclosures or attachments. Subcategories for different types
of enclosures and attachments are provided for further specificity.)
cdt:cdtEnclosedTranscribed
(The document contains at least one attachment or enclosure that has been transcribed.)
cdt:cdtEnclosedUntranscribed
(The document contains at least one attachment or enclosure that has not yet been transcribed.)
cdt:cdtEnclosedMissing
(The document originally contained one or more attachments or enclosures, which are
not in the file.)
cdt:cdtEnclosedMap
(The document contains at least one map as an attachment or enclosure.)
cdt:cdtEnclosedDraft
(The document contains at least one attachment or enclosure that is a draft of another
document.)
cdt:cdtEnclosedAct
(The document contains at least one attachment or enclosure that is an act of parliament.
These are usually printed.)
cdt:cdtEnclosedLaw
(The document contains at least one attachment or enclosure that is a legal document.)
cdt:cdtEnclosedCircular
(The document contains at least one attachment or enclosure that is a circular.)
cdt:cdtEnclosedArticle
(The document contains at least one attachment or enclosure that is an article from
a newspaper or similar publication.)
cdt:cdtEnclosedPamphlet
(The document contains at least one attachment or enclosure that is a pamphlet or similar
publication.)
cdt:cdtEnclosedAdvertisement
(The document contains at least one attachment or enclosure that is an advertisement
of some kind.)
cdt:cdtBornDigital
cdt:cdtDatabase
(Database-style documents such as personographies, placeographies, lists of page-images,
etc.)
cdt:cdtProsopography
(Biographical data on individuals in the correspondence.)
cdt:cdtVesselography
(Information on vessels mentioned in the correspondence.)
cdt:cdtPlaceography
(Information on geographical locations mentioned in the correspondence.)
cdt:cdtPageImages
(Lists of images of original correspondence-pages linked from the transcriptions.)
cdt:cdtWebContent
(Website pages (introductions, credits, and the like).)
cdt:cdtDocumentation
(Project documentation in XML format.)
scheme
identifies the classification scheme within which the set of categories concerned
is defined, for example by a <taxonomy> element, or by some other resource.
<category> (category) contains an individual descriptive category, possibly nested within a superordinate
category, within a user-defined taxonomy. [2.3.7. The Classification Declaration]
<row><cell role="label">General conduct</cell><cell role="data">Not satisfactory, on account of his great unpunctuality
and inattention to duties</cell></row>
The who attribute may be used to point to any other element, but will typically specify a
<respStmt> or <person> element elsewhere in the header, identifying the person responsible for the change
and their role in making it.
It is recommended that changes be recorded with the most recent first. The status attribute may be used to indicate the status of a document following the change documented.
<profileDesc><creation><listChange><change xml:id="DRAFT1">First draft in pencil</change><change xml:id="DRAFT2"
notBefore="1880-12-09">First revision, mostly
using green ink</change><change xml:id="DRAFT3"
notBefore="1881-02-13">Final corrections as
supplied to printer.</change></listChange></creation></profileDesc>
Because the children of a <choice> element all represent alternative ways of encoding the same sequence, it is natural
to think of them as mutually exclusive. However, there may be cases where a full representation
of a text requires the alternative encodings to be considered as parallel.
Where the purpose of an encoding is to record multiple witnesses of a single work,
rather than to identify multiple possible encoding decisions at a given point, the
<app> element and associated elements discussed in section 12.1. The Apparatus Entry, Readings, and Witnesses should be preferred.
Example
An American encoding of Gulliver's Travels which retains the British spelling but also provides a version regularized to American
spelling might be encoded as follows.
<p>Lastly, That, upon his solemn oath to observe all the above
articles, the said man-mountain shall have a daily allowance of
meat and drink sufficient for the support of <choice><sic>1724</sic><corr>1728</corr></choice> of our subjects,
with free access to our royal person, and other marks of our
<choice><orig>favour</orig><reg>favor</reg></choice>.</p>
<cit> (cited quotation) contains a quotation from some other document, together with a bibliographic reference
to its source. In a dictionary it may contain an example text with at least one occurrence
of the word form, used in the sense being described, or a translation of the headword,
or an example. [3.3.3. Quotation4.3.1. Grouped Texts9.3.5.1. Examples]
<cit><quote>and the breath of the whale is frequently attended with such an insupportable smell,
as to bring on disorder of the brain.</quote><bibl>Ulloa's South America</bibl></cit>
Example
<entry><form><orth>horrifier</orth></form><cit type="translation" xml:lang="en"><quote>to horrify</quote></cit><cit type="example"><quote>elle était horrifiée par la dépense</quote><cit type="translation" xml:lang="en"><quote>she was horrified at the expense.</quote></cit></cit></entry>
Example
<cit type="example"><quote xml:lang="mix">Ka'an yu tsa'a Pedro.</quote><media url="soundfiles-gen:S_speak_1s_on_behalf_of_Pedro_01_02_03_TS.wav"
mimeType="audio/wav"/><cit type="translation"><quote xml:lang="en">I'm speaking on behalf of Pedro.</quote></cit><cit type="translation"><quote xml:lang="es">Estoy hablando de parte de Pedro.</quote></cit></cit>
<classDecl><taxonomy xml:id="LCSH"><bibl>Library of Congress Subject Headings</bibl></taxonomy></classDecl><!-- ... --><textClass><keywords scheme="#LCSH"><term>Political science</term><term>United States -- Politics and government —
Revolution, 1775-1783</term></keywords></textClass>
<div type="letter"><p> perhaps you will favour me with a sight of it when convenient.</p><closer><salute>I remain, &c. &c.</salute><signed>H. Colburn</signed></closer></div>
Example
<div type="chapter"><p><!-- ... --> and his heart was going like mad and yes I said yes I will Yes.</p><closer><dateline><name type="place">Trieste-Zürich-Paris,</name><date>1914–1921</date></dateline></closer></div>
<correspAction> (correspondence action) contains a structured description of the place, the name of a person/organization
and the date related to the sending/receiving of a message or any other action related
to the correspondence. [2.4.6. Correspondence Description]
<correspContext> (correspondence context) provides references to preceding or following correspondence related to this piece
of correspondence. [2.4.6. Correspondence Description]
<correspContext><ref type="prev"
target="http://weber-gesamtausgabe.de/A040962"> Previous letter of
<persName>Carl Maria von Weber</persName> to
<persName>Caroline Brandt</persName>:
<date when="1816-12-30">December 30, 1816</date></ref><ref type="next"
target="http://weber-gesamtausgabe.de/A041003"> Next letter of
<persName>Carl Maria von Weber</persName> to
<persName>Caroline Brandt</persName>:
<date when="1817-01-05">January 5, 1817</date></ref></correspContext>
<correspDesc> (correspondence description) contains a description of the actions related to one act of correspondence. [2.4.6. Correspondence Description]
<correspDesc><correspAction type="sent"><persName>Carl Maria von Weber</persName><settlement>Dresden</settlement><date when="1817-06-23">23 June 1817</date></correspAction><correspAction type="received"><persName>Caroline Brandt</persName><settlement>Prag</settlement></correspAction><correspContext><ref type="prev"
target="http://www.weber-gesamtausgabe.de/A041209">Previous letter of
<persName>Carl Maria von Weber</persName>
to <persName>Caroline Brandt</persName>:
<date from="1817-06-19" to="1817-06-20">June 19/20, 1817</date></ref><ref type="next"
target="http://www.weber-gesamtausgabe.de/A041217">Next letter of
<persName>Carl Maria von Weber</persName> to
<persName>Caroline Brandt</persName>:
<date when="1817-06-27">June 27, 1817</date></ref></correspContext></correspDesc>
Given on the <date when="1977-06-12">Twelfth Day
of June in the Year of Our Lord One Thousand Nine Hundred and Seventy-seven of the
Republic
the Two Hundredth and first and of the University the Eighty-Sixth.</date>
<entry><form><orth>competitor</orth><hyph>com|peti|tor</hyph><pron>k@m"petit@(r)</pron></form><gramGrp><pos>n</pos></gramGrp><def>person who competes.</def></entry>
<del> (deletion) contains a letter, word, or passage deleted, marked as deleted, or otherwise indicated
as superfluous or spurious in the copy text by an author, scribe, or a previous annotator
or corrector. [3.5.3. Additions, Deletions, and Omissions]
This element should be used for deletion of shorter sequences of text, typically single
words or phrases. The <delSpan> element should be used for longer sequences of text, for those containing structural
subdivisions, and for those containing overlapping additions and deletions.
The text deleted must be at least partially legible in order for the encoder to be
able to transcribe it (unless it is restored in a <supplied> tag). Illegible or lost text within a deletion may be marked using the <gap> tag to signal that text is present but has not been transcribed, or is no longer
visible. Attributes on the <gap> element may be used to indicate how much text is omitted, the reason for omitting
it, etc. If text is not fully legible, the <unclear> element (available when using the additional tagset for transcription of primary
sources) should be used to signal the areas of text which cannot be read with confidence
in a similar way.
Degrees of uncertainty over what can still be read, or whether a deletion was intended
may be indicated by use of the <certainty> element (see 21. Certainty, Precision, and Responsibility).
There is a clear distinction in the TEI between <del> and <surplus> on the one hand and <gap> or <unclear> on the other. <del> indicates a deletion present in the source being transcribed, which states the author's
or a later scribe's intent to cancel or remove text. <surplus> indicates material present in the source being transcribed which should have been
so deleted, but which is not in fact. <gap> or <unclear>, by contrast, signal an editor's or encoder's decision to omit something or their
inability to read the source text. See sections 11.3.1.7. Text Omitted from or Supplied in the Transcription and 11.3.3.2. Use of the gap, del, damage, unclear, and supplied Elements in Combination for the relationship between these and other related elements used in detailed transcription.
Example
<l><del rend="overtyped">Mein</del> Frisch <del rend="overstrike" type="primary">schwebt</del>
weht der Wind
</l>
<desc> (description) contains a short description of the purpose, function, or use of its parent element,
or when the parent is a documentation element, describes or defines the object being
documented. [22.4.1. Description of Components]
(deprecation information) This element describes why or how its parent element is being deprecated, typically
including recommendations for alternate encoding.
<dataSpec module="tei"
ident="teidata.point"
validUntil="2050-02-25"><desc type="deprecationInfo"
versionDate="2018-09-14"
xml:lang="en">Several standards bodies, including NIST in the USA,
strongly recommend against ending the representation of a number
with a decimal point. So instead of <q>3.</q> use either <q>3</q>
or <q>3.0</q>.</desc><!-- ... --></dataSpec>
When used in a specification element such as <elementSpec>, TEI convention requires that this be expressed as a finite clause, begining with
an active verb.
Example
Example of a <desc> element inside a documentation element.
<dataSpec module="tei"
ident="teidata.point"><desc versionDate="2010-10-17"
xml:lang="en">defines the data type used to express a point in cartesian space.</desc><content><dataRef name="token"
restriction="(-?[0-9]+(\.[0-9]+)?,-?[0-9]+(\.[0-9]+)?)"/></content><!-- ... --></dataSpec>
Example
Example of a <desc> element in a non-documentation element.
A <desc> with a type of deprecationInfo should only occur when its parent element is being deprecated. Furthermore, it should
always occur in an element that is being deprecated when <desc> is a valid child of that element.
<sch:rule context="tei:desc[ @type eq 'deprecationInfo']">
<sch:assert test="../@validUntil">Information about a
deprecation should only be present in a specification element
that is being deprecated: that is, only an element that has a
@validUntil attribute should have a child <desc
type="deprecationInfo">.</sch:assert>
</sch:rule>
<body><div type="part"><head>Fallacies of Authority</head><p>The subject of which is Authority in various shapes, and the object, to repress all
exercise of the reasoning faculty.</p><div n="1" type="chapter"><head>The Nature of Authority</head><p>With reference to any proposed measures having for their object the greatest
happiness of the greatest number [...]</p><div n="1.1" type="section"><head>Analysis of Authority</head><p>What on any given occasion is the legitimate weight or influence to be attached to
authority [...] </p></div><div n="1.2" type="section"><head>Appeal to Authority, in What Cases Fallacious.</head><p>Reference to authority is open to the charge of fallacy when [...] </p></div></div></div></body>
Schematron
<sch:rule context="tei:div[@type = ('enclosure_list', 'enclosures_transcribed', 'marginalia',
'other_files')]">
<sch:let name="divType" value="@type"/>
<sch:let name="ancestorDivType"
value="ancestor::tei:div[@type = ('enclosure_list', 'enclosures_transcribed',
'marginalia', 'minutes', 'other_files')][1]/@type"/>
<sch:report test="ancestor::tei:div[@type = ('enclosure_list', 'enclosures_transcribed',
'marginalia', 'minutes', 'other_files')]"> This div with @type <sch:value-of select="$divType"/>
should not be nested inside a div with @type <sch:value-of select="$ancestorDivType"/>.
</sch:report>
</sch:rule>
<sch:rule context="tei:div[@type = 'minute_entry']">
<sch:assert test="parent::tei:div[@type='minutes']"> This minute_entry div should
be a child of a minutes div.
</sch:assert>
</sch:rule>
<sch:rule context="tei:div[@type = 'enclosure_entry']">
<sch:assert test="parent::tei:div[@type='enclosure_list']"> This enclosure_entry div
should be a child of an enclosure_list div.
</sch:assert>
</sch:rule>
<sch:rule context="tei:div[@type = 'enclosure_transcribed']">
<sch:assert test="parent::tei:div[@type='enclosures_transcribed']"> This enclosure_transcribed
div should be a child of an enclosures_transcribed div.
</sch:assert>
</sch:rule>
<sch:rule context="tei:div[@type = 'marginalis']">
<sch:assert test="parent::tei:div[@type='marginalia']"> This marginalis div should
be a child of a marginalia div.
</sch:assert>
</sch:rule>
<sch:rule context="tei:div[@type = 'other_entry']">
<sch:assert test="parent::tei:div[@type='other_files']"> This other_entry div should
be a child of an other_files div.
</sch:assert>
</sch:rule>
Schematron
<sch:report test="(ancestor::tei:l or ancestor::tei:lg) and not(ancestor::tei:floatingText)">
Abstract model violation: Lines may not contain higher-level structural elements such
as div, unless div is a descendant of floatingText.
</sch:report>
Schematron
<sch:report test="(ancestor::tei:p or ancestor::tei:ab) and not(ancestor::tei:floatingText)">
Abstract model violation: p and ab may not contain higher-level structural elements
such as div, unless div is a descendant of floatingText.
</sch:report>
<divGen> (automatically generated text division) indicates the location at which a textual division generated automatically by a text-processing
application is to appear. [3.9.2. Index Entries]
This element is intended primarily for use in document production or manipulation,
rather than in the transcription of pre-existing materials; it makes it easier to
specify the location of indices, tables of contents, etc., to be generated by text
preparation or word processing software.
Example
One use for this element is to allow document preparation software to generate an
index and insert it in the appropriate place in the output. The example below assumes
that the indexName attribute on <index> elements in the text has been used to specify index entries for the two generated
indexes, named NAMES and THINGS:
<editor> contains a secondary statement of responsibility for a bibliographic item, for example
the name of an individual, institution or organization, (or of several such) acting
as editor, compiler, translator, etc. [3.12.2.2. Titles, Authors, and Editors]
Particularly where cataloguing is likely to be based on the content of the header,
it is advisable to use generally recognized authority lists for the exact form of
personal names.
Example
<editor role="Technical_Editor">Ron Van den Branden</editor><editor role="Editor-in-Chief">John Walsh</editor><editor role="Managing_Editor">Anne Baillot</editor>
<egXML> (example of XML) a single XML fragment demonstrating the use of some XML, such as elements, attributes,
or processing instructions, etc., in which the <egXML> element functions as the root element. [22.1.1. Phrase Level Terms]
the example is intended to be fully valid, assuming that its root element, or a provided
root element, could have been used as a possible root element in the schema concerned.[Default]
feasible
the example could be transformed into a valid document by inserting any number of
valid attributes and child elements anywhere within it; or it is valid against a version
of the schema concerned in which the provision of character data, list, element, or
attribute values has been made optional.
false
the example is not intended to be valid, and contains deliberate errors.
In the source of the TEI Guidelines, this element declares itself and its content
as belonging to the namespace http://www.tei-c.org/ns/Examples. This enables the content of the element to be validated independently against the
TEI scheme. Where this element is used outside this context, a different namespace
or none at all may be preferable. The content must however be a well-formed XML fragment
or document: where this is not the case, the more general <eg> element should be used in preference.
Example
<egXML xmlns="http://www.tei-c.org/ns/Examples"><div><head>A slide about <gi>egXML</gi></head><list><item><gi>egXML</gi> can be used to give XML examples in the TEI
Examples namespace</item><item>Attributes values for <att>valid</att>:
<list rend="collapsed"><item><val rend="green">true</val>: intended to be fully
valid</item><item><val rend="amber">feasible</val>: valid if missing nodes
provided</item><item><val rend="red">false</val>: not intended to be valid</item></list></item><item>The <att>rend</att> attribute can be
used for recording how parts of the example were rendered.</item></list></div></egXML>
Example
<egXML valid="feasible" source="#UND" xmlns="http://www.tei-c.org/ns/Examples"><text><front><!-- front matter for the whole group --></front><group><text><!-- first text --></text><text><!-- second text --></text></group></text><!-- This example is not valid TEI, but could be made so by
adding missing components --></egXML>
Example
<egXML xmlns="http://www.tei-c.org/ns/Examples" valid="false">
<para xml:lang="en">Doubloons are a pirate's best friend</para>
</egXML>
<encodingDesc><p>Basic encoding, capturing lexical information only. All
hyphenation, punctuation, and variant spellings normalized. No
formatting or layout information preserved.</p></encodingDesc>
Like all elements, <entry> inherits an xml:id attribute from the class global. No restrictions are placed on the method used to construct xml:ids; one convenient method is to use the orthographic form of the headword, appending
a disambiguating number where necessary. Identification codes are sometimes included
on machine-readable tapes of dictionaries for in-house use.
It is recommended to use the <sense> element even for an entry that has only one sense to group together all parts of
the definition relating to the word sense since this leads to more consistent encoding
across entries.
Example
<entry><form><orth>disproof</orth><pron>dIs"pru:f</pron></form><gramGrp><pos>n</pos></gramGrp><sense n="1"><def>facts that disprove something.</def></sense><sense n="2"><def>the act of disproving.</def></sense></entry>
The content of this element should be the expanded abbreviation, usually (but not
always) a complete word or phrase. The <ex> element provided by the transcr module may be used to mark up sequences of letters supplied within such an expansion.
If abbreviations are expanded silently, this practice should be documented in the
<editorialDecl>, either with a <normalization> element or a <p>.
Example
The address is Southmoor
<choice><expan>Road</expan><abbr>Rd</abbr></choice>
<facsimile> contains a representation of some written source in the form of a set of images rather
than as transcribed or encoded text. [11.1. Digital Facsimiles]
<sch:rule context="tei:facsimile//tei:line | tei:facsimile//tei:zone">
<sch:report test="child::text()[ normalize-space(.) ne '']"> A facsimile element represents
a text with images, thus
transcribed text should not be present within it.
</sch:report>
<!--
What about:
* ellipses/supplied/text()
* writing
* label, formula, app, witDetail, metamark?
* notatedMusic?
* figure/[all-sorts-of-crazy-stuff-e.g.-entry]
* addSpan, damageSpan, delSpan
Or the fact that <front> and <back> (but not <body>) are
permitted inside <facsimile>, and thus *anything* can be
inside ther?
-->
</sch:rule>
The major source of information for those seeking to create a catalogue entry or bibliographic
citation for an electronic file. As such, it provides a title and statements of responsibility
together with details of the publication or distribution of the file, of any series
to which it belongs, and detailed bibliographic notes for matters not addressed elsewhere
in the header. It also contains a full bibliographic description for the source or
sources from which the electronic text was derived.
Example
<fileDesc><titleStmt><title>The shortest possible TEI document</title></titleStmt><publicationStmt><p>Distributed as part of TEI P5</p></publicationStmt><sourceDesc><p>No print source exists: this is an original digital text</p></sourceDesc></fileDesc>
<funder> (funding body) specifies the name of an individual, institution, or organization responsible for
the funding of a project or text. [2.2.1. The Title Statement]
Funders provide financial support for a project; they are distinct from sponsors (see element <sponsor>), who provide intellectual support and authority.
Example
<funder>The National Endowment for the Humanities, an independent federal agency</funder><funder>Directorate General XIII of the Commission of the European Communities</funder><funder>The Andrew W. Mellon Foundation</funder><funder>The Social Sciences and Humanities Research Council of Canada</funder>
<fw> (forme work) contains a running head (e.g. a header, footer), catchword, or similar material appearing
on the current page. [11.6. Headers, Footers, and Similar Matter]
Where running heads are consistent throughout a chapter or section, it is usually
more convenient to relate them to the chapter or section, e.g. by use of the rend attribute. The <fw> element is intended for cases where the running head changes from page to page, or
where details of page layout and the internal structure of the running heads are of
paramount importance.
Example
<fw type="sig" place="bottom">C3</fw>
Schematron
<sch:rule context="tei:fw[@type='catchword']">
<sch:assert test="not(matches(., 'catchword')) and not(normalize-space(.) = '')">
Replace the word "catchword" with the actual catchword as seen on original document.
This value cannot be empty. If there is no catchword remove the fw element.
</sch:assert>
</sch:rule>
<genName> (generational name component) contains a name component used to distinguish otherwise similar names on the basis
of the relative ages or generations of the persons named. [13.2.1. Personal Names]
<geo> (geographical coordinates) contains any expression of a set of geographic coordinates, representing a point,
line, or area on the surface of the earth in some notation. [13.3.4.1. Varieties of Location]
Uses of <geo> can be associated with a coordinate system, defined by a <geoDecl> element supplied in the TEI header, using the decls attribute. If no such link is made, the assumption is that the content of each <geo> element will be a pair of numbers separated by whitespace, to be interpreted as latitude
followed by longitude according to the World Geodetic System.
Example
<geoDecl xml:id="WGS" datum="WGS84">World Geodetic System</geoDecl><geoDecl xml:id="OS" datum="OSGB36">Ordnance Survey</geoDecl><!-- ... --><location><desc>A tombstone plus six lines of
Anglo-Saxon text, built into the west tower (on the south side
of the archway, at 8 ft. above the ground) of the
Church of St. Mary-le-Wigford in Lincoln.</desc><geo decls="#WGS">53.226658 -0.541254</geo><geo decls="#OS">SK 97481 70947</geo></location>
<p>The <gi>xhtml:li</gi> element is roughly analogous to the <gi>item</gi> element, as is the
<gi scheme="DBK">listItem</gi> element.</p>
This example shows the use of both a namespace prefix and the scheme attribute as alternative ways of indicating that the <gi> in question is not a TEI element name: in practice only one method should be adopted.
The mimeType attribute should be used to supply the MIME media type of the image specified by
the url attribute.
Within the body of a text, a <graphic> element indicates the presence of a graphic component in the source itself. Within
the context of a <facsimile> or <sourceDoc> element, however, a <graphic> element provides an additional digital representation of some part of the source
being encoded.
Example
<figure><graphic url="fig1.png"/><head>Figure One: The View from the Bridge</head><figDesc>A Whistleresque view showing four or five sailing boats in the foreground, and a
series of buoys strung out between them.</figDesc></figure>
<head> (heading) contains any type of heading, for example the title of a section, or the heading of
a list, glossary, manuscript description, etc. [4.2.1. Headings and Trailers]
The <head> element is used for headings at all levels; software which treats (e.g.) chapter
headings, section headings, and list titles differently must determine the proper
processing of a <head> element based on its structural position. A <head> occurring as the first element of a list is the title of that list; one occurring
as the first element of a <div1> is the title of that chapter or section.
Example
The most common use for the <head> element is to mark the headings of sections. In older writings, the headings or incipits may be rather longer than usual in modern works. If a section has an explicit ending
as well as a heading, it should be marked as a <trailer>, as in this example:
<div1 n="I" type="book"><head>In the name of Christ here begins the first book of the ecclesiastical history of
Georgius Florentinus, known as Gregory, Bishop of Tours.</head><div2 type="section"><head>In the name of Christ here begins Book I of the history.</head><p>Proposing as I do ...</p><p>From the Passion of our Lord until the death of Saint Martin four hundred and twelve
years passed.</p><trailer>Here ends the first Book, which covers five thousand, five hundred and ninety-six
years from the beginning of the world down to the death of Saint Martin.</trailer></div2></div1>
Example
When headings are not inline with the running text (see e.g. the heading "Secunda conclusio") they might however be encoded as if. The actual placement in the source document
can be captured with the place attribute.
<div type="subsection"><head place="margin">Secunda conclusio</head><p><lb n="1251"/><hi rend="large">Potencia: habitus: et actus: recipiunt speciem ab obiectis<supplied>.</supplied></hi><lb n="1252"/>Probatur sic. Omne importans necessariam habitudinem ad proprium
[...]
</p></div>
Example
The <head> element is also used to mark headings of other units, such as lists:
With a few exceptions, connectives are equally
useful in all kinds of discourse: description, narration, exposition, argument. <list rend="bulleted"><head>Connectives</head><item>above</item><item>accordingly</item><item>across from</item><item>adjacent to</item><item>again</item><item><!-- ... --></item></list>
<hi rend="gothic">And this Indenture further witnesseth</hi>
that the said <hi rend="italic">Walter Shandy</hi>, merchant,
in consideration of the said intended marriage ...
Schematron
<sch:rule context="tei:hi">
<sch:let name="textContent"
value="xs:string(.)"/>
<sch:assert role="error"
test="not(child::tei:hi[xs:string(.) = $textContent])">Do not nest hi elements; put
multiple CSS rules in the same hi element's style attribute.</sch:assert>
</sch:rule>
<idno> should be used for labels which identify an object or concept in a formal cataloguing
system such as a database or an RDF store, or in a distributed system such as the
World Wide Web. Some suggested values for type on <idno> are ISBN, ISSN, DOI, and URI.
In the last case, the identifier includes a non-Unicode character which is defined
elsewhere by means of a <glyph> or <char> element referenced here as #sym.
Schematron
<sch:rule context="tei:idno[@type='page']">
<sch:assert test="not(matches(., '\?\?\?')) and not(normalize-space(.) = '')"> Replace
"???" with a page number, this element cannot be empty either.
</sch:assert>
</sch:rule>
David's other principal backer, Josiah ha-Kohen
<index indexName="NAMES"><term>Josiah ha-Kohen b. Azarya</term></index> b. Azarya, son of one of the last gaons of Sura <index indexName="PLACES"><term>Sura</term></index> was David's own first cousin.
Whatever string of characters is used to label a list item in the copy text may be
used as the value of the global n attribute, but it is not required that numbering be recorded explicitly. In ordered
lists, the n attribute on the <item> element is by definition synonymous with the use of the <label> element to record the enumerator of the list item. In glossary lists, however, the
term being defined should be given with the <label> element, not n.
Example
<list rend="numbered"><head>Here begin the chapter headings of Book IV</head><item n="4.1">The death of Queen Clotild.</item><item n="4.2">How King Lothar wanted to appropriate one third of the Church revenues.</item><item n="4.3">The wives and children of Lothar.</item><item n="4.4">The Counts of the Bretons.</item><item n="4.5">Saint Gall the Bishop.</item><item n="4.6">The priest Cato.</item><item> ...</item></list>
Labels are commonly used for the headwords in glossary lists; note the use of the
global xml:lang attribute to set the default language of the glossary list to Middle English, and
identify the glosses and headings as modern English or Latin:
Labels may also be used to record explicitly the numbers or letters which mark list
items in ordered lists, as in this extract from Gibbon's Autobiography. In this usage the <label> element is synonymous with the n attribute on the <item> element:
I will add two facts, which have seldom occurred
in the composition of six, or at least of five quartos. <list rend="runon" type="ordered"><label>(1)</label><item>My first rough manuscript, without any intermediate copy, has been sent to the press.</item><label>(2) </label><item>Not a sheet has been seen by any human eyes, excepting those of the author and the
printer: the faults and the merits are exclusively my own.</item></list>
Example
Labels may also be used for other structured list items, as in this extract from the
journal of Edward Gibbon:
<list type="gloss"><label>March 1757.</label><item>I wrote some critical observations upon Plautus.</item><label>March 8th.</label><item>I wrote a long dissertation upon some lines of Virgil.</item><label>June.</label><item>I saw Mademoiselle Curchod — <quote xml:lang="la">Omnia vincit amor, et nos cedamus
amori.</quote></item><label>August.</label><item>I went to Crassy, and staid two days.</item></list>
Note that the <label> might also appear within the <item> rather than as its sibling. Though syntactically valid, this usage is not recommended
TEI practice.
Example
Labels may also be used to represent a label or heading attached to a paragraph or
sequence of paragraphs not treated as a structural division, or to a group of verse
lines. Note that, in this case, the <label> element appears within the <p> or <lg> element, rather than as a preceding sibling of it.
<p>[...]
<lb/>& n’entrer en mauuais & mal-heu-
<lb/>ré meſnage. Or des que le conſente-
<lb/>ment des parties y eſt le mariage eſt
<lb/> arreſté, quoy que de faict il ne ſoit
<label place="margin">Puiſſance maritale
entre les Romains.</label><lb/> conſommé. Depuis la conſomma-
<lb/>tion du mariage la femme eſt ſoubs
<lb/> la puiſſance du mary, s’il n’eſt eſcla-
<lb/>ue ou enfant de famille : car en ce
<lb/> cas, la femme, qui a eſpouſé vn en-
<lb/>fant de famille, eſt ſous la puiſſance
[...]</p>
In this example the text of the label appears in the right hand margin of the original
source, next to the paragraph it describes, but approximately in the middle of it.
If so desired the type attribute may be used to distinguish different categories of label.
By convention, <lb> elements should appear at the point in the text where a new line starts. The n attribute, if used, indicates the number or other value associated with the text
between this point and the next <lb> element, typically the sequence number of the line within the page, or other appropriate
unit. This element is intended to be used for marking actual line breaks on a manuscript
or printed page, at the point where they occur; it should not be used to tag structural
units such as lines of verse (for which the <l> element is available) except in circumstances where structural units cannot otherwise
be marked.
The type attribute may be used to characterize the line break in any respect. The more specialized
attributes break, ed, or edRef should be preferred when the intent is to indicate whether or not the line break
is word-breaking, or to note the source from which it derives.
Example
This example shows typographical line breaks within metrical lines, where they occur
at different places in different editions:
<l>Of Mans First Disobedience,<lb ed="1674"/> and<lb ed="1667"/> the Fruit</l><l>Of that Forbidden Tree, whose<lb ed="1667 1674"/> mortal tast</l><l>Brought Death into the World,<lb ed="1667"/> and all<lb ed="1674"/> our woe,</l>
Example
This example encodes typographical line breaks as a means of preserving the visual
appearance of a title page. The break attribute is used to show that the line break does not (as elsewhere) mark the start
of a new word.
<titlePart><lb/>With Additions, ne-<lb break="no"/>ver before Printed.
</titlePart>
Previous versions of these Guidelines recommended the use of type on <list> to encode the rendering or appearance of a list (whether it was bulleted, numbered,
etc.). The current recommendation is to use the rend or style attributes for these aspects of a list, while using type for the more appropriate task of characterizing the nature of the content of a list.
The formal syntax of the element declarations allows <label> tags to be omitted from lists tagged <list type="gloss">; this is however a semantic error.
May contain an optional heading followed by a series of items, or a series of label
and item pairs, the latter being optionally preceded by one or two specialized headings.
Example
<list rend="numbered"><item>a butcher</item><item>a baker</item><item>a candlestick maker, with
<list rend="bulleted"><item>rings on his fingers</item><item>bells on his toes</item></list></item></list>
Example
<list type="syllogism" rend="bulleted"><item>All Cretans are liars.</item><item>Epimenides is a Cretan.</item><item>ERGO Epimenides is a liar.</item></list>
Example
<list type="litany" rend="simple"><item>God save us from drought.</item><item>God save us from pestilence.</item><item>God save us from wickedness in high places.</item><item>Praise be to God.</item></list>
Example
The following example treats the short numbered clauses of Anglo-Saxon legal codes
as lists of items. The text is from an ordinance of King Athelstan (924–939):
<div1 type="section"><head>Athelstan's Ordinance</head><list rend="numbered"><item n="1">Concerning thieves. First, that no thief is to be spared who is caught with
the stolen goods, [if he is] over twelve years and [if the value of the goods
is]
over
eightpence.
<list rend="numbered"><item n="1.1">And if anyone does spare one, he is to pay for the thief with his
wergild — and the thief is to be no nearer a settlement on that account —
or to
clear himself by an oath of that amount.</item><item n="1.2">If, however, he [the thief] wishes to defend himself or to escape, he is
not to be spared [whether younger or older than twelve].</item><item n="1.3">If a thief is put into prison, he is to be in prison 40 days, and he may
then be redeemed with 120 shillings; and the kindred are to stand surety
for him
that he will desist for ever.</item><item n="1.4">And if he steals after that, they are to pay for him with his wergild,
or to bring him back there.</item><item n="1.5">And if he steals after that, they are to pay for him with his wergild,
whether to the king or to him to whom it rightly belongs; and everyone of
those who
supported him is to pay 120 shillings to the king as a fine.</item></list></item><item n="2">Concerning lordless men. And we pronounced about these lordless men, from whom
no justice can be obtained, that one should order their kindred to fetch back
such
a
person to justice and to find him a lord in public meeting.
<list rend="numbered"><item n="2.1">And if they then will not, or cannot, produce him on that appointed day,
he is then to be a fugitive afterwards, and he who encounters him is to strike
him
down as a thief.</item><item n="2.2">And he who harbours him after that, is to pay for him with his wergild
or to clear himself by an oath of that amount.</item></list></item><item n="3">Concerning the refusal of justice. The lord who refuses justice and upholds
his guilty man, so that the king is appealed to, is to repay the value of the
goods
and
120 shillings to the king; and he who appeals to the king before he demands justice
as
often as he ought, is to pay the same fine as the other would have done, if he
had
refused him justice.
<list rend="numbered"><item n="3.1">And the lord who is an accessory to a theft by his slave, and it becomes
known about him, is to forfeit the slave and be liable to his wergild on
the first
occasionp if he does it more often, he is to be liable to pay all that he
owns.</item><item n="3.2">And likewise any of the king's treasurers or of our reeves, who has been
an accessory of thieves who have committed theft, is to liable to the same.</item></list></item><item n="4">Concerning treachery to a lord. And we have pronounced concerning treachery to
a lord, that he [who is accused] is to forfeit his life if he cannot deny it
or is
afterwards convicted at the three-fold ordeal.</item></list></div1>
Note that nested lists have been used so the tagging mirrors the structure indicated
by the two-level numbering of the clauses. The clauses could have been treated as
a one-level list with irregular numbering, if desired.
Example
<p>These decrees, most blessed Pope Hadrian, we propounded in the public council ...
and they
confirmed them in our hand in your stead with the sign of the Holy Cross, and afterwards
inscribed with a careful pen on the paper of this page, affixing thus the sign of
the Holy
Cross.
<list rend="simple"><item>I, Eanbald, by the grace of God archbishop of the holy church of York, have
subscribed to the pious and catholic validity of this document with the sign
of the
Holy
Cross.</item><item>I, Ælfwold, king of the people across the Humber, consenting have subscribed with
the sign of the Holy Cross.</item><item>I, Tilberht, prelate of the church of Hexham, rejoicing have subscribed with the
sign of the Holy Cross.</item><item>I, Higbald, bishop of the church of Lindisfarne, obeying have subscribed with the
sign of the Holy Cross.</item><item>I, Ethelbert, bishop of Candida Casa, suppliant, have subscribed with thef sign of
the Holy Cross.</item><item>I, Ealdwulf, bishop of the church of Mayo, have subscribed with devout will.</item><item>I, Æthelwine, bishop, have subscribed through delegates.</item><item>I, Sicga, patrician, have subscribed with serene mind with the sign of the Holy
Cross.</item></list></p>
Schematron
<sch:rule context="tei:list[@type='gloss']">
<sch:assert test="tei:label">The content of a "gloss" list should include a sequence
of one or more pairs of a label element followed by an item element</sch:assert>
</sch:rule>
<listBibl><head>Works consulted</head><bibl>Blain, Clements and Grundy: Feminist Companion to
Literature in English (Yale, 1990)
</bibl><biblStruct><analytic><title>The Interesting story of the Children in the Wood</title></analytic><monogr><title>The Penny Histories</title><author>Victor E Neuberg</author><imprint><publisher>OUP</publisher><date>1968</date></imprint></monogr></biblStruct></listBibl>
<listOrg> (list of organizations) contains a list of elements, each of which provides information about an identifiable
organization. [13.2.2. Organizational Names]
The type attribute may be used to distinguish lists of organizations of a particular
type if convenient.
Example
<listOrg><head>Libyans</head><org><orgName>Adyrmachidae</orgName><desc>These people have, in most points, the same customs as the Egyptians, but
use the costume of the Libyans. Their women wear on each leg a ring made of
bronze [...]</desc></org><org><orgName>Nasamonians</orgName><desc>In summer they leave their flocks and herds upon the sea-shore, and go up
the country to a place called Augila, where they gather the dates from the
palms [...]</desc></org><org><orgName>Garamantians</orgName><desc>[...] avoid all society or intercourse with their fellow-men, have no
weapon of war, and do not know how to defend themselves. [...]</desc><!-- ... --></org></listOrg>
<listPlace> (list of places) contains a list of places, optionally followed by a list of relationships (other than
containment) defined amongst them. [2.2.7. The Source Description13.3.4. Places]
<listPlace type="offshoreIslands"><place><placeName>La roche qui pleure</placeName></place><place><placeName>Ile aux cerfs</placeName></place></listPlace>
<listPrefixDef> (list of prefix definitions) contains a list of definitions of prefixing schemes used in teidata.pointer values, showing how abbreviated URIs using each scheme may be expanded into full
URIs. [16.2.3. Using Abbreviated Pointers]
In this example, two private URI scheme prefixes are defined and patterns are provided
for dereferencing them. Each prefix is also supplied with a human-readable explanation
in a <p> element.
<listPrefixDef><prefixDef ident="psn"
matchPattern="([A-Z]+)"
replacementPattern="personography.xml#$1"><p> Private URIs using the <code>psn</code>
prefix are pointers to <gi>person</gi>
elements in the personography.xml file.
For example, <code>psn:MDH</code>
dereferences to <code>personography.xml#MDH</code>.
</p></prefixDef><prefixDef ident="bibl"
matchPattern="([a-z]+[a-z0-9]*)"
replacementPattern="http://www.example.com/getBibl.xql?id=$1"><p> Private URIs using the <code>bibl</code> prefix can be
expanded to form URIs which retrieve the relevant
bibliographical reference from www.example.com.
</p></prefixDef></listPrefixDef>
<location> (location) defines the location of a place as a set of geographical coordinates, in terms of
other named geo-political entities, or as an address. [13.3.4. Places]
<place xml:id="BGbuilding" type="building"><placeName>Brasserie Georges</placeName><location><country key="FR"/><settlement type="city">Lyon</settlement><district type="arrondissement">IIème</district><district type="quartier">Perrache</district><placeName type="street"><num>30</num>, Cours de Verdun</placeName></location></place>
Example
<place type="imaginary"><placeName>Atlantis</placeName><location><offset>beyond</offset><placeName>The Pillars of <persName>Hercules</persName></placeName></location></place>
There is thus a
striking accentual difference between a verbal form like <mentioned xml:id="X234" xml:lang="el">eluthemen</mentioned><gloss target="#X234">we were released,</gloss> accented on the second syllable of the
word, and its participial derivative
<mentioned xml:id="X235" xml:lang="el">lutheis</mentioned><gloss target="#X235">released,</gloss> accented on the last.
<milestone> (milestone) marks a boundary point separating any kind of section of a text, typically but not
necessarily indicating a point at which some part of a standard reference system changes,
where the change is not represented by a structural element. [3.11.3. Milestone Elements]
For this element, the global n attribute indicates the new number or other value for the unit which changes at this
milestone. The special value unnumbered should be used in passages which fall outside the normal numbering scheme, such as
chapter or other headings, poem numbers or titles, etc.
The order in which <milestone> elements are given at a given point is not normally significant.
Proper nouns referring to people, places, and organizations may be tagged instead
with <persName>, <placeName>, or <orgName>, when the TEI module for names and dates is included.
Example
<name type="person">Thomas Hoccleve</name><name type="place">Villingaholt</name><name type="org">Vetus Latina Institut</name><name type="person" ref="#HOC001">Occleve</name>
Schematron
<sch:rule context="tei:name[@key]">
<sch:assert test="matches(@key, '^[a-z0-9_\-]+$')"> The @key attribute must have a
value consisting
of lower-case letters and underscores, and cannot
be empty. The @key attribute must point to a
person, place or vessel.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:name[@key] | tei:orgName[@key]">
<sch:assert test="not(ancestor::tei:name[@key] or ancestor::tei:orgName[@key])"> Do
not nest one name element inside another.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:name[@type='ip']">
<sch:assert test="@subtype = ('group', 'individual')"> If you make a name @type='ip'
(Indigenous People/Person)
then you must supply @subtype="group" or @subtype="individual".
</sch:assert>
</sch:rule>
In the following example, the translator has supplied a footnote containing an explanation
of the term translated as "painterly":
And yet it is not only
in the great line of Italian renaissance art, but even in the
painterly <note place="bottom" type="gloss"
resp="#MDMH"><term xml:lang="de">Malerisch</term>. This word has, in the German, two
distinct meanings, one objective, a quality residing in the object,
the other subjective, a mode of apprehension and creation. To avoid
confusion, they have been distinguished in English as
<mentioned>picturesque</mentioned> and
<mentioned>painterly</mentioned> respectively.
</note> style of the
Dutch genre painters of the seventeenth century that drapery has this
psychological significance.
<!-- elsewhere in the document --><respStmt xml:id="MDMH"><resp>translation from German to English</resp><name>Hottinger, Marie Donald Mackie</name></respStmt>
For this example to be valid, the code MDMH must be defined elsewhere, for example by means of a responsibility statement in
the
associated TEI header.
Example
The global n attribute may be used to supply the symbol or number used to mark the note's point
of attachment in the source text, as in the following example:
Mevorakh b. Saadya's mother, the matriarch of the
family during the second half of the eleventh century, <note n="126" anchored="true"> The
alleged mention of Judah Nagid's mother in a letter from 1071 is, in fact, a reference
to
Judah's children; cf. above, nn. 111 and 54. </note> is well known from Geniza documents
published by Jacob Mann.
However, if notes are numbered in sequence and their numbering can be reconstructed
automatically by processing software, it may well be considered unnecessary to record
the note numbers.
<notesStmt> (notes statement) collects together any notes providing information about a text additional to that
recorded in other parts of the bibliographic description. [2.2.6. The Notes Statement2.2. The File Description]
<opener> (opener) groups together dateline, byline, salutation, and similar phrases appearing as a preliminary
group at the start of a division, especially of a letter. [4.2. Elements Common to All Divisions]
<opener><dateline>Walden, this 29. of August 1592</dateline></opener>
Example
<opener><dateline><name type="place">Great Marlborough Street</name><date>November 11, 1848</date></dateline><salute>My dear Sir,</salute></opener><p>I am sorry to say that absence from town and other circumstances have prevented me
from
earlier enquiring...</p>
<org> (organization) provides information about an identifiable organization such as a business, a tribe,
or any other grouping of people. [13.3.3. Organizational Data]
Values for this attribute may be locally defined by a project, using arbitrary keywords
such as artist, employer, familyGroup, or politicalParty, each of which should be associated with a definition. Such local definitions will
typically be provided by a <desc> for each <valItem> element in the schema specification of the project's customization.
<org xml:id="JAMs"><orgName>Justified Ancients of Mummu</orgName><desc>An underground anarchist collective spearheaded by
<persName>Hagbard Celine</persName>, who fight the Illuminati
from a golden submarine, the <name>Leif Ericson</name></desc><bibl><author>Robert Shea</author><author>Robert Anton Wilson</author><title>The Illuminatus! Trilogy</title></bibl></org>
About a year back, a question of considerable interest was agitated in the <orgName key="PAS1" type="voluntary"><placeName key="PEN">Pennsyla.</placeName> Abolition Society
</orgName> [...]
Schematron
<sch:rule context="tei:org">
<sch:assert role="error"
test="tei:desc[string-length(normalize-space(.)) gt 10] or tei:orgName/@type"> If
there is no descriptive information for an org, please add @type to the orgName.
</sch:assert>
</sch:rule>
If all that is desired is to call attention to the original version in the copy text,
<orig> may be used alone:
<l>But this will be a <orig>meere</orig> confusion</l><l>And hardly shall we all be <orig>vnderstoode</orig></l>
Example
More usually, an <orig> will be combined with a regularized form within a <choice> element:
<l>But this will be a <choice><orig>meere</orig><reg>mere</reg></choice> confusion</l><l>And hardly shall we all be <choice><orig>vnderstoode</orig><reg>understood</reg></choice></l>
<p>Hallgerd was outside. <q>There is blood on your axe,</q> she said. <q>What have you
done?</q></p><p><q>I have now arranged that you can be married a second time,</q> replied Thjostolf.
</p><p><q>Then you must mean that Thorvald is dead,</q> she said.
</p><p><q>Yes,</q> said Thjostolf. <q>And now you must think up some plan for me.</q></p>
Schematron
<sch:report test="(ancestor::tei:ab or ancestor::tei:p) and not( ancestor::tei:floatingText
|parent::tei:exemplum |parent::tei:item |parent::tei:note |parent::tei:q
|parent::tei:quote |parent::tei:remarks |parent::tei:said |parent::tei:sp
|parent::tei:stage |parent::tei:cell |parent::tei:figure )"> Abstract model violation:
Paragraphs may not occur inside other paragraphs or ab elements.
</sch:report>
Schematron
<sch:report test="(ancestor::tei:l or ancestor::tei:lg) and not( ancestor::tei:floatingText
|parent::tei:figure |parent::tei:note )"> Abstract model violation: Lines may not
contain higher-level structural elements such as div, p, or ab, unless p is a child
of figure or note, or is a descendant of floatingText.
</sch:report>
<particDesc> (participation description) describes the identifiable speakers, voices, or other participants in any kind of
text or other persons named or otherwise referred to in a text, edition, or metadata. [15.2. Contextual Information]
May contain a prose description organized as paragraphs, or a structured list of persons
and person groups, with an optional formal specification of any relationships amongst
them.
Example
<particDesc><listPerson><person xml:id="P-1234" sex="2" age="mid"><p>Female informant, well-educated, born in
Shropshire UK, 12 Jan 1950, of unknown occupation. Speaks French fluently.
Socio-Economic status B2.</p></person><person xml:id="P-4332" sex="1"><persName><surname>Hancock</surname><forename>Antony</forename><forename>Aloysius</forename><forename>St John</forename></persName><residence notAfter="1959"><address><street>Railway Cuttings</street><settlement>East Cheam</settlement></address></residence><occupation>comedian</occupation></person><listRelation><relation type="personal" name="spouse"
mutual="#P-1234 #P-4332"/></listRelation></listPerson></particDesc>
This example shows both a very simple person description, and a very detailed one,
using some of the more specialized elements from the module for Names and Dates.
The Despatches project uses the facs attribute to specify a link to the page-image for the page following the break.
Example
<pb facs="co_60_22/co_60_22_00055r.jpg"/>
Schematron
<sch:rule context="tei:pb">
<sch:assert test="not(@n)"> Don't use @n for links to page-images. Use @facs instead.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:pb">
<sch:assert test="not(parent::tei:table or parent::tei:row)"> Page breaks cannot appear
as children of table elements
or row elements. Put them inside cells.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:pb">
<sch:assert test="not(matches(@facs, '\s'))"> Spaces are not allowed in @facs.
</sch:assert>
</sch:rule>
<persName> (personal name) contains a proper noun or proper-noun phrase referring to a person, possibly including
one or more of the person's forenames, surnames, honorifics, added names, etc. [13.2.1. Personal Names]
<persName><forename>Edward</forename><forename>George</forename><surname type="linked">Bulwer-Lytton</surname>, <roleName>Baron Lytton of
<placeName>Knebworth</placeName></roleName></persName>
Schematron
<sch:rule context="tei:persName[parent::tei:person]">
<sch:assert test="not(text()[following-sibling::tei:*[not(preceding-sibling::tei:*)]])">
No text or whitespace before first child element of a bio persName.
</sch:assert>
</sch:rule>
Values for this attribute may be locally defined by a project, using arbitrary keywords
such as artist, employer, author, relative, or servant, each of which should be associated with a definition. Such local definitions will
typically be provided by a <valList> element in the project schema specification.
sex
specifies the sex of the person.
Status
Optional
Datatype
1–∞ occurrences ofteidata.sexseparated by whitespace
Note
Values for this attribute may be defined locally by a project, or they may refer to
an external standard.
May contain either a prose description organized as paragraphs, or a sequence of more
specific demographic elements drawn from the model.personPart class.
Example
<person sex="F" age="adult"><p>Female respondent, well-educated, born in Shropshire UK, 12 Jan 1950, of unknown occupation.
Speaks French fluently. Socio-Economic
status B2.</p></person>
Values for this attribute may be locally defined by a project, using arbitrary keywords
such as movement, employers, relatives, or servants, each of which should be associated with a definition. Such local definitions will
typically be provided by a <valList> element in the project schema specification.
May contain a prose description organized as paragraphs, or any sequence of demographic
elements in any combination.
The global xml:id attribute should be used to identify each speaking participant in a spoken text if
the who attribute is specified on individual utterances.
This constraint ensures that once a place has been researched, the type attribute
is not left on it in error.
<sch:rule context="tei:placeName[@type = 'unavailable']">
<sch:assert role="error"
test="not(following-sibling::tei:desc[string-length(normalize-space(.))
gt 10])"> There appears to be some content in the desc element for this place, so
it should not be marked as 'unavailable'.
</sch:assert>
</sch:rule>
<sch:rule context="tei:placeName[@type = 'incomplete']">
<sch:assert role="error"
test="not(following-sibling::tei:desc[child::tei:listBibl])"> This place description
includes references, so it is presumably
complete or rudimentary, and should not be marked 'incomplete'.
</sch:assert>
</sch:rule>
<sch:rule context="tei:placeName[@type = 'rudimentary']">
<sch:assert role="error"
test="following-sibling::tei:desc[child::tei:listBibl]"> This place description does
not include references, so it
is presumably incomplete, and should not be marked 'rudimentary'.
The value 'rudimentary' is intended for items which are complete,
but which might benefit from more research.
</sch:assert>
</sch:rule>
<prefixDef> (prefix definition) defines a prefixing scheme used in teidata.pointer values, showing how abbreviated URIs using the scheme may be expanded into full URIs. [16.2.3. Using Abbreviated Pointers]
supplies a name which functions as the prefix for an abbreviated pointing scheme such
as a private URI scheme. The prefix constitutes the text preceding the first colon.
The abbreviated pointer may be dereferenced to produce either an absolute or a relative
URI reference. In the latter case it is combined with the value of xml:base in force at the place where the pointing attribute occurs to form an absolute URI
in the usual manner as prescribed by XML Base.
Example
<prefixDef ident="ref"
matchPattern="([a-z]+)"
replacementPattern="../../references/references.xml#$1"><p> In the context of this project, private URIs with
the prefix "ref" point to <gi>div</gi> elements in
the project's global references.xml file.
</p></prefixDef>
<profileDesc> (text-profile description) provides a detailed description of non-bibliographic aspects of a text, specifically
the languages and sublanguages used, the situation in which it was produced, the participants
and their setting. [2.4. The Profile Description2.1.1. The TEI Header and Its Components]
Although the content model permits it, it is rarely meaningful to supply multiple
occurrences for any of the child elements of <profileDesc> unless these are documenting multiple texts.
Where a publication statement contains several members of the model.publicationStmtPart.agency or model.publicationStmtPart.detail classes rather than one or more paragraphs or anonymous blocks, care should be taken
to ensure that the repeated elements are presented in a meaningful order. It is a
conformance requirement that elements supplying information about publication place,
address, identifier, availability, and date be given following the name of the publisher,
distributor, or authority concerned, and preferably in that order.
Example
<publicationStmt><publisher>C. Muquardt </publisher><pubPlace>Bruxelles & Leipzig</pubPlace><date when="1846"/></publicationStmt>
Example
<publicationStmt><publisher>Chadwyck Healey</publisher><pubPlace>Cambridge</pubPlace><availability><p>Available under licence only</p></availability><date when="1992">1992</date></publicationStmt>
Example
<publicationStmt><publisher>Zea Books</publisher><pubPlace>Lincoln, NE</pubPlace><date>2017</date><availability><p>This is an open access work licensed under a Creative Commons Attribution 4.0 International
license.</p></availability><ptr target="http://digitalcommons.unl.edu/zeabook/55"/></publicationStmt>
<q> (quoted) contains material which is distinguished from the surrounding text using quotation
marks or a similar method, for any one of a variety of reasons including, but not
limited to: direct speech or thought, technical terms or jargon, authorial distance,
quotations from elsewhere, and passages that are mentioned but not used. [3.3.3. Quotation]
May be used to indicate that a passage is distinguished from the surrounding text
for reasons concerning which no claim is made. When used in this manner, <q> may be thought of as syntactic sugar for <hi> with a value of rend that indicates the use of such mechanisms as quotation marks.
Example
It is spelled <q>Tübingen</q> — to enter the
letter <q>u</q> with an umlaut hold down the <q>option</q> key and press
<q>0 0 f c</q>
<quote> (quotation) contains a phrase or passage attributed by the narrator or author to some agency external
to the text. [3.3.3. Quotation4.3.1. Grouped Texts]
If a bibliographic citation is supplied for the source of a quotation, the two may
be grouped using the <cit> element.
Example
Lexicography has shown little sign of being affected by the
work of followers of J.R. Firth, probably best summarized in his
slogan, <quote>You shall know a word by the company it
keeps</quote><ref>(Firth, 1957)</ref>
The target and cRef attributes are mutually exclusive.
Example
See especially <ref target="http://www.natcorp.ox.ac.uk/Texts/A02.xml#s2">the second
sentence</ref>
Example
See also <ref target="#locution">s.v. <term>locution</term></ref>.
Schematron
<sch:rule context="tei:ref[@target]">
<sch:assert test="not(matches(@target, '\s'))"> ERROR: target attributes must not
contain spaces.
</sch:assert>
<sch:assert test="not(contains(@target, 'bcgenesis'))"> ERROR: target attributes must
never have a hard-coded link
to bcgenesis.uvic.ca. Use a cdc: link.
</sch:assert>
<sch:assert test="not(matches(@target, 'cdc:[^\.]\.scx'))"> ERROR: target attributes
using the cdc: link scheme do not
need ".scx" at the end.
</sch:assert>
<sch:assert test="not(matches(., '(^\s)|(\s$)'))"> ERROR: Do not include leading or
trailing spaces in ref elements.
</sch:assert>
</sch:rule>
Schematron
<sch:report test="@target and @cRef">Only one of the
attributes @target' and @cRef' may be supplied on <sch:name/>
</sch:report>
If all that is desired is to call attention to the fact that the copy text has been
regularized, <reg> may be used alone:
<q>Please <reg>knock</reg> if an <reg>answer</reg> is <reg>required</reg></q>
Example
It is also possible to identify the individual responsible for the regularization,
and, using the <choice> and <orig> elements, to provide both the original and regularized readings:
<q>Please <choice><reg resp="#LB">knock</reg><orig>cnk</orig></choice> if an <choice><reg>answer</reg><orig>nsr</orig></choice> is <choice><reg>required</reg><orig>reqd</orig></choice></q>
<rendition> (rendition) supplies information about the rendition or appearance of one or more elements in
the source text. [2.3.4. The Tagging Declaration]
contains a selector or series of selectors specifying the elements to which the contained
style description applies, expressed in the language specified in the scheme attribute.
Since the default value of the scheme attribute is assumed to be CSS, the default expectation for this attribute, in the
absence of scheme, is that CSS selector syntax will be used.
While rendition is used to point from an element in the transcribed source to a <rendition> element in the header which describes how it appears, the selector attribute allows the encoder to point in the other direction: from a <rendition> in the header to a collection of elements which all share the same renditional features.
In both cases, the intention is to record the appearance of the source text, not to
prescribe any particular output rendering.
The attribute ref, inherited from the class att.canonical may be used to indicate the kind of responsibility in a normalized form by referring
directly to a standardized list of responsibility types, such as that maintained by
a naming authority, for example the list maintained at http://www.loc.gov/marc/relators/relacode.html for bibliographic usage.
<respStmt> (statement of responsibility) supplies a statement of responsibility for the intellectual content of a text, edition,
recording, or series, where the specialized elements for authors, editors, etc. do
not suffice or do not apply. May also be used to encode information about individuals
or organizations which have played a role in the production or distribution of a bibliographic
work. [3.12.2.2. Titles, Authors, and Editors2.2.1. The Title Statement2.2.2. The Edition Statement2.2.5. The Series Statement]
If present on this element, the status attribute should indicate the current status of the document. The same attribute
may appear on any <change> to record the status at the time of that change. Conventionally <change> elements should be given in reverse date order, with the most recent change at the
start of the list.
<roleName> (role name) contains a name component which indicates that the referent has a particular role
or position in society, such as an official title or rank. [13.2.1. Personal Names]
A <roleName> may be distinguished from an <addName> by virtue of the fact that, like a title, it typically exists independently of its
holder.
Example
<persName><forename>William</forename><surname>Poulteny</surname><roleName>Earl of Bath</roleName></persName>
Example
<p>The <roleName role="solicitor_general">S.G.</roleName> is the only national public official,
including the Supreme Court justices, required by statute to be “learned in the law.”</p>
Example
<p><persName ref="#NJF"><roleName role="solicitor_general">Solicitor General</roleName> Noel J. Francisco</persName>,
representing the administration, asserted in rebuttal that there was nothing to disavow
(...)
<persName ref="#NJF">Francisco</persName> had violated the scrupulous standard of candor about the facts and
the law that <roleName role="solicitor_general">S.G.s</roleName>, in Republican and Democratic administrations
alike, have repeatedly said they must honor.
</p>
<q>My dear <rs type="person">Mr. Bennet</rs>, </q> said <rs type="person">his lady</rs>
to him one day,
<q>have you heard that <rs type="place">Netherfield Park</rs> is let at
last?</q>
<salute> (salutation) contains a salutation or greeting prefixed to a foreword, dedicatory epistle, or other
division of a text, or the salutation in the closing of a letter, preface, etc. [4.2.2. Openers and Closers]
(This identifies a segment as an "interesting snippet".) "Interesting snippets" are harvested by the build process and turned into a JSON file
which is used to drive the home page snippet function.
disclaimerIP
(This identifies the Indigenous Peoples disclaimer segment in the acknowledgement page.) This segment is placed as a disclaimer on pages containing references to Indigenous
Peoples and points them to the Glossary of terms. Segment needs "This document contains"
prepended before it.
The <seg> element may be used at the encoder's discretion to mark any segments of the text
of interest for processing. One use of the element is to mark text features for which
no appropriate markup is otherwise defined. Another use is to provide an identifier
for some segment which is to be pointed at by some other element—i.e. to provide a
target, or a part of a target, for a <ptr> or other similar element.
Example
<seg>When are you leaving?</seg><seg>Tomorrow.</seg>
Example
<s><seg rend="caps" type="initial-cap">So father's only</seg> glory was the ballfield.
</s>
Example
<seg type="preamble"><seg>Sigmund, <seg type="patronym">the son of Volsung</seg>, was a king in Frankish country.</seg><seg>Sinfiotli was the eldest of his sons ...</seg><seg>Borghild, Sigmund's wife, had a brother ... </seg></seg>
<sense> groups together all information relating to one word sense in a dictionary entry,
for example definitions, examples, and translation equivalents. [9.2. The Structure of Dictionary Entries]
May contain character data mixed with any other elements defined in the dictionary
tag set.
Example
<sense n="2"><usg type="time">Vx.</usg><def>Vaillance, bravoure (spécial., au combat)</def><cit type="example"><quote>La valeur n'attend pas le nombre des années</quote><bibl><author>Corneille</author></bibl></cit></sense>
<signed> (signature) contains the closing salutation, etc., appended to a foreword, dedicatory epistle,
or other division of a text. [4.2.2. Openers and Closers]
<soCalled> (so called) contains a word or phrase for which the author or narrator indicates a disclaiming
of responsibility, for example by the use of scare quotes or italics. [3.3.3. Quotation]
To edge his way along
the crowded paths of life, warning all human sympathy to keep its distance, was what
the
knowing ones call <soCalled>nuts</soCalled> to Scrooge.
<sourceDesc> (source description) describes the source(s) from which an electronic text was derived or generated, typically
a bibliographic description in the case of a digitized text, or a phrase such as "born
digital" for a text which has no previous existence. [2.2.7. The Source Description]
<sourceDesc><bibl><title level="a">The Interesting story of the Children in the Wood</title>. In
<author>Victor E Neuberg</author>, <title>The Penny Histories</title>.
<publisher>OUP</publisher><date>1968</date>. </bibl></sourceDesc>
Example
<sourceDesc><p>Born digital: no previous source exists.</p></sourceDesc>
<styleDefDecl> (style definition language declaration) specifies the name of the formal language in which style or renditional information
is supplied elsewhere in the document. The specific version of the scheme may also
be supplied. [2.3.5. The Default Style Definition Language Declaration]
<supplied> (supplied) signifies text supplied by the transcriber or editor for any reason; for example because
the original cannot be read due to physical damage, or because of an obvious omission
by the author or scribe. [11.3.3.1. Damage, Illegibility, and Supplied Text]
<surface> defines a written surface as a two-dimensional coordinate space, optionally grouping
one or more graphic representations of that space, zones of interest within that space,
and transcriptions of the writing within them. [11.1. Digital Facsimiles11.2.2. Embedded Transcription]
The <surface> element represents any two-dimensional space on some physical surface forming part
of the source material, such as a piece of paper, a face of a monument, a billboard,
a scroll, a leaf etc.
The coordinate space defined by this element may be thought of as a grid lrx - ulx units wide and uly - lry units high.
The <surface> element may contain graphic representations or transcriptions of written zones, or
both. The coordinate values used by every <zone> element contained by this element are to be understood with reference to the same
grid.
Where it is useful or meaningful to do so, any grouping of multiple <surface> elements may be indicated using the <surfaceGrp> element.
TEI recommended practice is to specify this attribute. When the <tagUsage> elements inside <tagsDecl> are used to list each of the element types in the associated <text>, the value should be given as false. When the <tagUsage> elements inside <tagsDecl> are used to provide usage information or default renditions for only a subset of
the elements types within the associated <text>, the value should be true.
If the partial attribute were not specified here, the implication would be that the document in
question
contains only <hi>, <title>, and <para> elements.
<taxonomy> (taxonomy) defines a typology either implicitly, by means of a bibliographic citation, or explicitly
by a structured taxonomy. [2.3.7. The Classification Declaration]
One of the few elements unconditionally required in any TEI document.
Example
<teiHeader><fileDesc><titleStmt><title>Shakespeare: the first folio (1623) in electronic form</title><author>Shakespeare, William (1564–1616)</author><respStmt><resp>Originally prepared by</resp><name>Trevor Howard-Hill</name></respStmt><respStmt><resp>Revised and edited by</resp><name>Christine Avern-Carr</name></respStmt></titleStmt><publicationStmt><distributor>Oxford Text Archive</distributor><address><addrLine>13 Banbury Road, Oxford OX2 6NN, UK</addrLine></address><idno type="OTA">119</idno><availability><p>Freely available on a non-commercial basis.</p></availability><date when="1968">1968</date></publicationStmt><sourceDesc><bibl>The first folio of Shakespeare, prepared by Charlton Hinman (The Norton Facsimile,
1968)</bibl></sourceDesc></fileDesc><encodingDesc><projectDesc><p>Originally prepared for use in the production of a series of old-spelling
concordances in 1968, this text was extensively checked and revised for use
during
the
editing of the new Oxford Shakespeare (Wells and Taylor, 1989).</p></projectDesc><editorialDecl><correction><p>Turned letters are silently corrected.</p></correction><normalization><p>Original spelling and typography is retained, except that long s and ligatured
forms are not encoded.</p></normalization></editorialDecl><refsDecl xml:id="ASLREF"><cRefPattern matchPattern="(\S+) ([^.]+)\.(.*)"
replacementPattern="#xpath(//div1[@n='$1']/div2/[@n='$2']//lb[@n='$3'])"><p>A reference is created by assembling the following, in the reverse order as that
listed here: <list><item>the <att>n</att> value of the preceding <gi>lb</gi></item><item>a period</item><item>the <att>n</att> value of the ancestor <gi>div2</gi></item><item>a space</item><item>the <att>n</att> value of the parent <gi>div1</gi></item></list></p></cRefPattern></refsDecl></encodingDesc><revisionDesc><list><item><date when="1989-04-12">12 Apr 89</date> Last checked by CAC</item><item><date when="1989-03-01">1 Mar 89</date> LB made new file</item></list></revisionDesc></teiHeader>
When this element appears within an <index> element, it is understood to supply the form under which an index entry is to be
made for that location. Elsewhere, it is understood simply to indicate that its content
is to be regarded as a technical or specialised term. It may be associated with a
<gloss> element by means of its ref attribute; alternatively a <gloss> element may point to a <term> element by means of its target attribute.
In formal terminological work, there is frequently discussion over whether terms must
be atomic or may include multi-word lexical items, symbolic designations, or phraseological
units. The <term> element may be used to mark any of these. No position is taken on the philosophical
issue of what a term can be; the looser definition simply allows the <term> element to be used by practitioners of any persuasion.
As with other members of the att.canonical class, instances of this element occuring in a text may be associated with a canonical
definition, either by means of a URI (using the ref attribute), or by means of some system-specific code value (using the key attribute). Because the mutually exclusive target and cRef attributes overlap with the function of the ref attribute, they are deprecated and may be removed at a subsequent release.
Example
A computational device that infers structure
from grammatical strings of words is known as a <term>parser</term>, and much of the history
of NLP over the last 20 years has been occupied with the design of parsers.
Example
We may define <term xml:id="TDPV1" rend="sc">discoursal point of view</term> as
<gloss target="#TDPV1">the relationship, expressed
through discourse structure, between the implied author or some other addresser, and
the
fiction.</gloss>
Example
We may define <term ref="#TDPV2" rend="sc">discoursal point of view</term> as
<gloss xml:id="TDPV2">the relationship, expressed
through discourse structure, between the implied author or some other addresser, and
the
fiction.</gloss>
Example
We discuss Leech's concept of <term ref="myGlossary.xml#TDPV2" rend="sc">discoursal point of view</term> below.
<text> (text) contains a single text of any kind, whether unitary or composite, for example a poem
or drama, a collection of essays, a novel, a dictionary, or a corpus sample. [4. Default Text Structure15.1. Varieties of Composite Text]
This element should not be used to represent a text which is inserted at an arbitrary
point within the structure of another, for example as in an embedded or quoted narrative;
the <floatingText> is provided for this purpose.
Example
<text><front><docTitle><titlePart>Autumn Haze</titlePart></docTitle></front><body><l>Is it a dragonfly or a maple leaf</l><l>That settles softly down upon the water?</l></body></text>
Example
The body of a text may be replaced by a group of nested texts, as in the following
schematic:
<text><front><!-- front matter for the whole group --></front><group><text><!-- first text --></text><text><!-- second text --></text></group></text>
<textClass> (text classification) groups information which describes the nature or topic of a text in terms of a standard
classification scheme, thesaurus, etc. [2.4.3. The Text Classification]
<taxonomy><category xml:id="acprose"><catDesc>Academic prose</catDesc></category><!-- other categories here --></taxonomy><!-- ... --><textClass><catRef target="#acprose"/><classCode scheme="http://www.udcc.org">001.9</classCode><keywords scheme="http://authorities.loc.gov"><list><item>End of the world</item><item>History - philosophy</item></list></keywords></textClass>
The level of a title is sometimes implied by its context: for example, a title appearing
directly within an <analytic> element is ipso facto of level “a”, and one appearing within a <series> element of level “s”. For this reason, the level attribute is not required in contexts where its value can be unambiguously inferred.
Where it is supplied in such contexts, its value should not contradict the value implied
by its parent element.
The attributes key and ref, inherited from the class att.canonical may be used to indicate the canonical form for the title; the former, by supplying
(for example) the identifier of a record in some external library system; the latter
by pointing to an XML element somewhere containing the canonical form of the title.
Example
<title>Information Technology and the Research Process: Proceedings of
a conference held at Cranfield Institute of Technology, UK,
18–21 July 1989</title>
Example
<title>Hardy's Tess of the D'Urbervilles: a machine readable
edition</title>
Example
<title type="full"><title type="main">Synthèse</title><title type="sub">an international journal for
epistemology, methodology and history of
science</title></title>
<titleStmt><title>Capgrave's Life of St. John Norbert: a machine-readable transcription</title><respStmt><resp>compiled by</resp><name>P.J. Lucas</name></respStmt></titleStmt>
The same element is used for all cases of uncertainty in the transcription of element
content, whether for written or spoken material. For other aspects of certainty, uncertainty,
and reliability of tagging and transcription, see chapter 21. Certainty, Precision, and Responsibility.
The position of every zone for a given surface is always defined by reference to the
coordinate system defined for that surface.
A graphic element contained by a zone represents the whole of the zone.
A zone may be of any shape. The attribute points may be used to define a polygonal zone, using the coordinate system defined by its
parent surface.
A zone is always a closed polygon. Repeating the initial coordinate at the end of
the sequence is optional. To encode an unclosed path, use the <path> element.
model.emphLikegroups phrase-level elements which are typographically distinct and to which a specific
function can be attributed. [3.3. Highlighting and Quotation]
Members of this class typically contain related parts of a dictionary entry which
form a coherent subdivision, for example a particular sense, homonym, etc.
Elements in this class are typically used to hold groups of links or of abstract interpretations,
or by provide indications of certainty etc. It may find be convenient to localize
all metadata elements, for example to contain them within the same divison as the
elements that they relate to; or to locate them all to a division of their own. They
may however appear at any point in a TEI text.
model.hiLikegroups phrase-level elements which are typographically distinct but to which no specific
function can be attributed. [3.3. Highlighting and Quotation]
model.limitedPhrasegroups phrase-level elements excluding those elements primarily intended for transcription
of existing sources. [1.3. The TEI Class System]
model.measureLikegroups elements which denote a number, a quantity, a measurement, or similar piece
of text that conveys some numerical meaning. [3.6.3. Numbers and Measures]
model.pPart.editorialgroups phrase-level elements for simple editorial interventions that may be useful
both in transcribing and in authoring. [3.5. Simple Editorial Changes]
model.pPart.transcriptionalgroups phrase-level elements used for editorial transcription of pre-existing source
materials. [3.5. Simple Editorial Changes]
model.persStateLikegroups elements describing changeable characteristics of a person which have a definite
duration, for example occupation, residence, or name.
This class of elements can occur within paragraphs, list items, lines of verse, etc.
Appendix A.2.59 model.phrase.xml
model.phrase.xmlgroups phrase-level elements used to encode XML constructs such as element names,
attribute names, and attribute values [22. Documentation Elements]
The ‘agency’ child elements, while not required, are required if one of the ‘detail’
child elements is to be used. It is not valid to have a ‘detail’ child element without
a preceding ‘agency’ child element.
The principles on which segmentation is carried out, and any special codes or attribute
values used, should be defined explicitly in the <segmentation> element of the <encodingDesc> within the associated TEI header.
Appendix A.2.71 model.teiHeaderPart
model.teiHeaderPartgroups high level elements which may appear more than once in a TEI header.
In the following example from Mary Pix's The False Friend, speeches (<sp>) in the body of the play are linked to <castItem> elements in the <castList> using the toWhom attribute, which is used to specify who the speech is directed to. Additionally,
the <stage> includes toWhom to indicate the directionality of the action.
<castItem type="role"><role xml:id="emil">Emilius.</role></castItem><castItem type="role"><role xml:id="lov">Lovisa</role></castItem><castItem type="role"><role xml:id="serv">A servant</role></castItem><!-- ... --><sp who="#emil"
toWhom="#lov"><speaker>Emil.</speaker><l n="1">My love!</l></sp><sp who="#lov"
toWhom="#emil"><speaker>Lov.</speaker><l n="2">I have no Witness of my Noble Birth</l><stage who="emil"
toWhom="#serv">Pointing to her Woman.</stage><l>But that poor helpless wretch——</l></sp>
Note
To indicate the recipient of written correspondence, use the elements used in section
2.4.6. Correspondence Description, rather than a toWhom attribute.
Appendix A.3.2 att.canonical
att.canonicalprovides attributes that can be used to associate a representation such as a name
or title with canonical information about the object being named or referenced. [13.1.1. Linking Names and Their Referents]
<author><name key="Hugo, Victor (1802-1885)"
ref="http://www.idref.fr/026927608">Victor Hugo</name></author>
Note
The value may be a unique identifier from a database, or any other externally-defined
string identifying the referent.
No particular syntax is proposed for the values of the key attribute, since its form will depend entirely on practice within a given project.
For the same reason, this attribute is not recommended in data interchange, since
there is no way of ensuring that the values used by one project are distinct from
those used by another. In such a situation, a preferable approach for magic tokens
which follows standard practice on the Web is to use a ref attribute whose value is a tag URI as defined in RFC 4151.
ref
(reference) provides an explicit means of locating a full definition or identity for the entity
being named by means of one or more URIs.
The value must point directly to one or more XML elements or other resources by means
of one or more URIs, separated by whitespace. If more than one is supplied the implication
is that the name identifies several distinct entities.
Appendix A.3.3 att.datable
att.datableprovides attributes for normalization of elements that contain dates, times, or datable
events. [3.6.4. Dates and Times13.4. Dates]
<sch:rule context="tei:*[@calendar]">
<sch:assert test="string-length( normalize-space(.) ) gt 0"> @calendar indicates one
or more
systems or calendars to which the date represented by the content of this element
belongs,
but this <sch:name/> element has no textual content.</sch:assert>
</sch:rule>
Note
This ‘superclass’ provides attributes that can be used to provide normalized values
of temporal information. By default, the attributes from the att.datable.w3c class are provided. If the module for names & dates is loaded, this class also provides
attributes from the att.datable.iso and att.datable.custom classes. In general, the possible values of attributes restricted to the W3C datatypes
form a subset of those values available via the ISO 8601 standard. However, the greater
expressiveness of the ISO datatypes may not be needed, and there exists much greater
software support for the W3C datatypes.
Appendix A.3.4 att.datable.w3c
att.datable.w3cprovides attributes for normalization of elements that contain datable events conforming
to the W3C XML Schema Part 2: Datatypes Second Edition. [3.6.4. Dates and Times13.4. Dates]
Examples of W3C date, time, and date & time formats.
<p><date when="1945-10-24">24 Oct 45</date><date when="1996-09-24T07:25:00Z">September 24th, 1996 at 3:25 in the morning</date><time when="1999-01-04T20:42:00-05:00">Jan 4 1999 at 8 pm</time><time when="14:12:38">fourteen twelve and 38 seconds</time><date when="1962-10">October of 1962</date><date when="--06-12">June 12th</date><date when="---01">the first of the month</date><date when="--08">August</date><date when="2006">MMVI</date><date when="0056">AD 56</date><date when="-0056">56 BC</date></p>
This list begins in
the year 1632, more precisely on Trinity Sunday, i.e. the Sunday after
Pentecost, in that year the
<date calendar="#julian"
when="1632-06-06">27th of May (old style)</date>.
<sch:rule context="tei:*[@when]">
<sch:report test="@notBefore|@notAfter|@from|@to"
role="nonfatal">The @when attribute cannot be used with any other att.datable.w3c
attributes.</sch:report>
</sch:rule>
Schematron
<sch:rule context="tei:*[@from]">
<sch:report test="@notBefore"
role="nonfatal">The @from and @notBefore attributes cannot be used together.</sch:report>
</sch:rule>
Schematron
<sch:rule context="tei:*[@to]">
<sch:report test="@notAfter"
role="nonfatal">The @to and @notAfter attributes cannot be used together.</sch:report>
</sch:rule>
Example
<date from="1863-05-28" to="1863-06-01">28 May through 1 June 1863</date>
Note
The value of these attributes should be a normalized representation of the date, time,
or combined date & time intended, in any of the standard formats specified by XML Schema Part 2: Datatypes Second Edition, using the Gregorian calendar.
The most commonly-encountered format for the date portion of a temporal attribute
is yyyy-mm-dd, but yyyy, --mm, ---dd, yyyy-mm, or --mm-dd may also be used. For the time part, the form hh:mm:ss is used.
Note that this format does not currently permit use of the value 0000 to represent the year 1 BCE; instead the value -0001 should be used.
Appendix A.3.5 att.dimensions
att.dimensionsprovides attributes for describing the size of physical objects.
The members of this attribute class are typically used to represent any kind of editorial
intervention in a text, for example a correction or interpretation, or to date or
localize manuscripts etc.
Each pointer on the source (if present) corresponding to a witness or witness group should reference a bibliographic
citation such as a <witness>, <msDesc>, or <bibl> element, or another external bibliographic citation, documenting the source concerned.
(homograph) groups information relating to one homograph within an entry.
xref
(cross reference) a reduced entry whose only function is to point to another main entry (e.g. for forms
of an irregular verb or for variant spellings: was pointing to be, or esthete to aesthete).
affix
an entry for a prefix, infix, or suffix.
abbr
(abbreviation) an entry for an abbreviation.
supplemental
a supplemental entry (for use in dictionaries which issue supplements to their main
work in which they include updated information about entries).
foreign
an entry for a foreign word in a monolingual dictionary.
Note
The global n attribute may be used to encode the homograph numbers attached to entries for homographs.
Appendix A.3.9 att.global
att.globalprovides attributes common to all elements in the TEI encoding scheme. [1.3.1.1. Global Attributes]
The value of this attribute is always understood to be a single token, even if it
contains space or other punctuation characters, and need not be composed of numbers
only. It is typically used to specify the numbering of chapters, sections, list items,
etc.; it may also be used in the specification of a standard reference system for
the text.
xml:lang
(language) indicates the language of the element content using a ‘tag’ generated according to
BCP 47.
<p> … The consequences of
this rapid depopulation were the loss of the last
<foreign xml:lang="rap">ariki</foreign> or chief
(Routledge 1920:205,210) and their connections to
ancestral territorial organization.</p>
Note
The xml:lang value will be inherited from the immediately enclosing element, or from its parent,
and so on up the document hierarchy. It is generally good practice to specify xml:lang at the highest appropriate level, noticing that a different default may be needed
for the <teiHeader> from that needed for the associated resource element or elements, and that a single
TEI document may contain texts in many languages.
Only attributes with free text values (rare in these guidelines) will be in the scope
of xml:lang.
The value used must conform with BCP 47. If the value is a private use code (i.e.,
starts with x- or contains -x-), a <language> element with a matching value for its ident attribute should be supplied in the TEI header to document this value. Such documentation
may also optionally be supplied for non-private-use codes, though these must remain
consistent with their (IETF)Internet Engineering Task Force definitions.
Appendix A.3.10 att.global.facs
att.global.facsprovides attributes used to express correspondence between an element and all or part
of a facsimile image or surface. [11.1. Digital Facsimiles]
<group><text xml:id="t1-g1-t1"
xml:lang="mi"><body xml:id="t1-g1-t1-body1"><div type="chapter"><head>He Whakamaramatanga mo te Ture Hoko, Riihi hoki, i nga Whenua Maori, 1876.</head><p>…</p></div></body></text><text xml:id="t1-g1-t2"
xml:lang="en"><body xml:id="t1-g1-t2-body1"
corresp="#t1-g1-t1-body1"><div type="chapter"><head>An Act to regulate the Sale, Letting, and Disposal of Native Lands, 1876.</head><p>…</p></div></body></text></group>
In this example a <group> contains two <text>s, each containing the same document in a different language. The correspondence is
indicated using corresp. The language is indicated using xml:lang, whose value is inherited; both the tag with the corresp and the tag pointed to by the corresp inherit the value from their immediate parent.
<!-- In a placeography called "places.xml" --><place xml:id="LOND1"
corresp="people.xml#LOND2 people.xml#GENI1"><placeName>London</placeName><desc>The city of London...</desc></place><!-- In a literary personography called "people.xml" --><person xml:id="LOND2"
corresp="places.xml#LOND1 #GENI1"><persName type="lit">London</persName><note><p>Allegorical character representing the city of <placeName ref="places.xml#LOND1">London</placeName>.</p></note></person><person xml:id="GENI1"
corresp="places.xml#LOND1 #LOND2"><persName type="lit">London’s Genius</persName><note><p>Personification of London’s genius. Appears as an
allegorical character in mayoral shows.
</p></note></person>
In this example, a <place> element containing information about the city of London is linked with two <person> elements in a literary personography. This correspondence represents a slightly looser
relationship than the one in the preceding example; there is no sense in which an
allegorical character could be substituted for the physical city, or vice versa, but
there is obviously a correspondence between them.
next
points to the next element of a virtual aggregate of which the current element is
part.
(rendition) indicates how the element in question was rendered or presented in the source text.
Status
Optional
Datatype
1–∞ occurrences ofteidata.wordseparated by whitespace
<head rend="align(center) case(allcaps)"><lb/>To The <lb/>Duchesse <lb/>of <lb/>Newcastle,
<lb/>On Her <lb/><hi rend="case(mixed)">New Blazing-World</hi>.
</head>
Note
These Guidelines make no binding recommendations for the values of the rend attribute; the characteristics of visual presentation vary too much from text to
text and the decision to record or ignore individual characteristics varies too much
from project to project. Some potentially useful conventions are noted from time to
time at appropriate points in the Guidelines. The values of the rend attribute are a set of sequence-indeterminate individual tokens separated by whitespace.
style
contains an expression in some formal style definition language which defines the
rendering or presentation used for this element in the source text
<head style="text-align: center; font-variant: small-caps"><lb/>To The <lb/>Duchesse <lb/>of <lb/>Newcastle, <lb/>On Her
<lb/><hi style="font-variant: normal">New Blazing-World</hi>.
</head>
Note
Unlike the attribute values of rend, which uses whitespace as a separator, the style attribute may contain whitespace. This attribute is intended for recording inline
stylistic information concerning the source, not any particular output.
The formal language in which values for this attribute are expressed may be specified
using the <styleDefDecl> element in the TEI header.
If style and rendition are both present on an element, then style overrides or complements rendition. style should not be used in conjunction with rend, because the latter does not employ a formal style definition language.
rendition
points to a description of the rendering or presentation used for this element in
the source text.
The rendition attribute is used in a very similar way to the class attribute defined for XHTML but with the important distinction that its function
is to describe the appearance of the source text, not necessarily to determine how
that text should be presented on screen or paper.
If rendition is used to refer to a style definition in a formal language like CSS, it is recommended
that it not be used in conjunction with rend. Where both rendition and rend are supplied, the latter is understood to override or complement the former.
Each URI provided should indicate a <rendition> element defining the intended rendition in terms of some appropriate style language,
as indicated by the scheme attribute.
To reduce the ambiguity of a resp pointing directly to a person or organization, we recommend that resp be used to point not to an agent (<person> or <org>) but to a <respStmt>, <author>, <editor> or similar element which clarifies the exact role played by the agent. Pointing to
multiple <respStmt>s allows the encoder to specify clearly each of the roles played in part of a TEI
file (creating, transcribing, encoding, editing, proofing etc.).
Example
Blessed are the
<choice><sic>cheesemakers</sic><corr resp="#editor" cert="high">peacemakers</corr></choice>: for they shall be called the children of God.
Example
<!-- in the <text> ... --><lg><!-- ... --><l>Punkes, Panders, baſe extortionizing
sla<choice><sic>n</sic><corr resp="#JENS1_transcriber">u</corr></choice>es,</l><!-- ... --></lg><!-- in the <teiHeader> ... --><!-- ... --><respStmt xml:id="JENS1_transcriber"><resp when="2014">Transcriber</resp><name>Janelle Jenstad</name></respStmt>
<sch:rule context="tei:*[@source]">
<sch:let name="srcs"
value="tokenize( normalize-space(@source),' ')"/>
<sch:report test="( self::tei:classRef | self::tei:dataRef | self::tei:elementRef
|
self::tei:macroRef | self::tei:moduleRef | self::tei:schemaSpec )
and $srcs[2]"> When used on a schema description element (like
<sch:value-of select="name(.)"/>), the @source attribute
should have only 1 value. (This one has <sch:value-of select="count($srcs)"/>.)
</sch:report>
</sch:rule>
Note
The source attribute points to an external source. When used on an element describing a schema
component (<classRef>, <dataRef>, <elementRef>, <macroRef>, <moduleRef>, or <schemaSpec>), it identifies the source from which declarations for the components should be obtained.
On other elements it provides a pointer to the bibliographical source from which a
quotation or citation is drawn.
In either case, the location may be provided using any form of URI, for example an
absolute URI, a relative URI, a private scheme URI of the form tei:x.y.z, where x.y.z indicates the version number, e.g. tei:4.3.2 for TEI P5 release 4.3.2 or (as a special case) tei:current for whatever is the latest release, or a private scheme URI that is expanded to an
absolute URI as documented in a <prefixDef>.
When used on elements describing schema components, source should have only one value; when used on other elements multiple values are permitted.
Example
<p><!-- ... --> As Willard McCarty (<bibl xml:id="mcc_2012">2012, p.2</bibl>) tells us, <quote source="#mcc_2012">‘Collaboration’ is a problematic and should be a contested
term.</quote><!-- ... --></p>
Example
<p><!-- ... --><quote source="#chicago_15_ed">Grammatical theories are in flux, and the more we learn, the
less we seem to know.</quote><!-- ... --></p><!-- ... --><bibl xml:id="chicago_15_ed"><title level="m">The Chicago Manual of Style</title>,
<edition>15th edition</edition>. <pubPlace>Chicago</pubPlace>: <publisher>University of
Chicago Press</publisher> (<date>2003</date>), <biblScope unit="page">p.147</biblScope>.
</bibl>
Example
<elementRef key="p" source="tei:2.0.1"/>
Include in the schema an element named <p> available from the TEI P5 2.0.1 release.
Example
<schemaSpec ident="myODD"
source="mycompiledODD.xml"><!-- further declarations specifying the components required --></schemaSpec>
Create a schema using components taken from the file mycompiledODD.xml.
Appendix A.3.15 att.lexicographic
att.lexicographicprovides a set of attributes for specifying standard and normalized values, grammatical
functions, alternate or equivalent forms, and information about composite parts. [9.2. The Structure of Dictionary Entries]
(location) indicates an <anchor> element typically elsewhere in the document, but possibly in another document, which
is the original location of this component.
may be used to specify further information about the entity referenced by this name
in the form of a set of whitespace-separated values, for example the occupation of
a person, or the status of a place.
The syntax used should follow that defined by W3C XPath syntax. Note that parenthesized groups are used not only for establishing order of precedence
and atoms for quantification, but also for creating subpatterns to be referenced by
the replacementPattern attribute.
replacementPattern
specifies a ‘replacement pattern’, that is, the skeleton of a relative or absolute
URI containing references to groups
in the matchPattern which, once subpattern substitution has been performed, complete the URI.
The strings $1, $2 etc. are references to the corresponding group in the regular expression specified
by matchPattern (counting open parenthesis, left to right). Processors are expected to replace them
with whatever matched the corresponding group in the regular expression.
If a digit preceded by a dollar sign is needed in the actual replacement pattern (as
opposed to being used as a back reference), the dollar sign must be written as %24.
Appendix A.3.21 att.personal
att.personal (attributes for components of names usually, but not necessarily, personal names) common attributes for those elements which form part of a name usually, but not necessarily,
a personal name. [13.2.1. Personal Names]
to the right, e.g. to the right of a vertical line of text, or to the right of a figure
below
below the line
left
to the left, e.g. to the left of a vertical line of text, or to the left of a figure
end
at the end of e.g. chapter or volume.
inline
within the body of the text.
inspace
in a predefined space, for example left by an earlier scribe.
<add place="margin">[An addition written in the margin]</add><add place="bottom opposite">[An addition written at the
foot of the current page and also on the facing page]</add>
One or more syntactically valid URI references, separated by whitespace. Because whitespace
is used to separate URIs, no whitespace is permitted inside a single URI. If a whitespace
character is required in a URI, it should be escaped with the normal mechanism, e.g.
TEI%20Consortium.
Schematron
<sch:rule context="tei:*[not(self::tei:schemaSpec)][@targetLang]">
<sch:assert test="@target">@targetLang should only be used on <sch:name/> if @target
is specified.</sch:assert>
</sch:rule>
Appendix A.3.24 att.resourced
att.resourcedprovides attributes by which a resource (such as an externally held media file) may
be located.
att.sortableprovides attributes for elements in lists or groups that are sortable, but whose sorting
key cannot be derived mechanically from the element content. [9.1. Dictionary Body and Overall Structure]
David's other principal backer, Josiah
ha-Kohen <index indexName="NAMES"><term sortKey="Azarya_Josiah_Kohen">Josiah ha-Kohen b. Azarya</term></index> b. Azarya, son of one of the last gaons of Sura was David's own first
cousin.
Note
The sort key is used to determine the sequence and grouping of entries in an index.
It provides a sequence of characters which, when sorted with the other values, will
produced the desired order; specifics of sort key construction are application-dependent
Dictionary order often differs from the collation sequence of machine-readable character
sets; in English-language dictionaries, an entry for 4-H will often appear alphabetized under “fourh”, and McCoy may be alphabetized under “maccoy”, while A1, A4, and A5 may all appear in numeric order ‘alphabetized’ between “a-” and “AA”. The sort key is required if the orthography of the dictionary entry does not suffice
to determine its location.
Appendix A.3.27 att.styleDef
att.styleDefprovides attributes to specify the name of a formal definition language used to provide
formatting or rendition information.
<sch:rule context="tei:*[@schemeVersion]">
<sch:assert test="@scheme and not(@scheme = 'free')"> @schemeVersion can only be used
if @scheme is specified.
</sch:assert>
</sch:rule>
Note
If schemeVersion is used, then scheme should also appear, with a value other than free.
When this attribute is specified on a row, its value is the default for all cells
in this row. When specified on a cell, its value overrides any default specified by
the role attribute of the parent <row> element.
rows
(rows) indicates the number of rows occupied by this cell or row.
A value greater than one indicates that this cell spans several rows. Where several
cells span multiple rows, it may be more convenient to use nested tables.
cols
(columns) indicates the number of columns occupied by this cell or row.
A value greater than one indicates that this cell or row spans several columns. Where
an initial cell spans an entire row, it may be better treated as a heading.
Appendix A.3.29 att.transcriptional
att.transcriptionalprovides attributes specific to elements encoding authorial or scribal intervention
in a text when transcribing manuscript or similar sources. [11.3.1.4. Additions and Deletions]
<div type="verse"><head>Night in Tarras</head><lg type="stanza"><l>At evening tramping on the hot white road</l><l>…</l></lg><lg type="stanza"><l>A wind sprang up from nowhere as the sky</l><l>…</l></lg></div>
Note
The type attribute is present on a number of elements, not all of which are members of att.typed, usually because these elements restrict the possible values for the attribute in
a specific way.
subtype
(subtype) provides a sub-categorization of the element, if needed
The subtype attribute may be used to provide any sub-classification for the element additional
to that provided by its type attribute.
Schematron
<sch:rule context="tei:*[@subtype]">
<sch:assert test="@type">The <sch:name/> element should not be categorized in detail
with @subtype unless also categorized in general with @type</sch:assert>
</sch:rule>
Note
When appropriate, values from an established typology should be used. Alternatively
a typology may be defined in the associated TEI header. If values are to be taken
from a project-specific list, this should be defined using the <valList> element in the project-specific schema description, as described in 23.3.1.3. Modification of Attribute and Attribute Value Lists .
Appendix A.3.31 att.written
att.writtenprovides attributes to indicate the hand in which the content of an element was written
in the source being transcribed. [1.3.1. Attribute Classes]
macro.limitedContent (paragraph content) defines the content of prose elements that are not used for transcription of extant
materials. [1.3. The TEI Class System]
macro.phraseSeq.limited (limited phrase sequence) defines a sequence of character data and those phrase-level elements that are not
typically used for transcribing extant documents. [1.4.1. Standard Content Models]
macro.specialPara ('special' paragraph content) defines the content model of elements such as notes or list items, which either contain
a series of component-level elements or else have the same structure as a paragraph,
containing a series of phrase-level and inter-level elements. [1.3. The TEI Class System]
Certainty may be expressed by one of the predefined symbolic values high, medium, or low. The value unknown should be used in cases where the encoder does not wish to assert an opinion about
the matter.
Appendix A.5.2 teidata.count
teidata.countdefines the range of attribute values used for a non-negative integer value used as
a count.
Attributes using this datatype must contain a single ‘word’ which contains only letters,
digits, punctuation characters, or symbols: thus it cannot include whitespace.
Typically, the list of documented possibilities will be provided (or exemplified)
by a value list in the associated attribute specification, expressed with a <valList> element.
Appendix A.5.4 teidata.gender
teidata.genderdefines the range of attribute values used to represent the gender of a person, persona,
or character.
teidata.languagedefines the range of attribute values used to identify a particular combination of
human language and writing system. [6.1. Language Identification]
The values for this attribute are language ‘tags’ as defined in BCP 47. Currently BCP 47 comprises RFC 5646 and RFC 4647; over time, other IETF documents
may succeed these as the best current practice.
A ‘language tag’, per BCP 47, is assembled from a sequence of components or subtags separated by the hyphen character (-, U+002D). The tag is made of the following subtags, in the following order. Every
subtag except the first is optional. If present, each occurs only once, except the
fourth and fifth components (variant and extension), which are repeatable.
language
The IANA-registered code for the language. This is almost always the same as the ISO
639 2-letter language code if there is one. The list of available registered language
subtags can be found at http://www.iana.org/assignments/language-subtag-registry. It is recommended that this code be written in lower case.
script
The ISO 15924 code for the script. These codes consist of 4 letters, and it is recommended
they be written with an initial capital, the other three letters in lower case. The
canonical list of codes is maintained by the Unicode Consortium, and is available
at http://unicode.org/iso15924/iso15924-codes.html. The IETF recommends this code be omitted unless it is necessary to make a distinction
you need.
region
Either an ISO 3166 country code or a UN M.49 region code that is registered with IANA
(not all such codes are registered, e.g. UN codes for economic groupings or codes
for countries for which there is already an ISO 3166 2-letter code are not registered).
The former consist of 2 letters, and it is recommended they be written in upper case;
the list of codes can be searched or browsed at https://www.iso.org/obp/ui/#search/code/. The latter consist of 3 digits; the list of codes can be found at http://unstats.un.org/unsd/methods/m49/m49.htm.
variant
An IANA-registered variation. These codes are used to indicate additional, well-recognized variations that define a language
or its dialects that are not covered by other available subtags.
extension
An extension has the format of a single letter followed by a hyphen followed by additional
subtags. These exist to allow for future extension to BCP 47, but as of this writing
no such extensions are in use.
private use
An extension that uses the initial subtag of the single letter x (i.e., starts with x-) has no meaning except as negotiated among the parties involved. These should be
used with great care, since they interfere with the interoperability that use of RFC
4646 is intended to promote. In order for a document that makes use of these subtags
to be TEI-conformant, a corresponding <language> element must be present in the TEI header.
There are two exceptions to the above format. First, there are language tags in the
IANA registry that do not match the above syntax, but are present because they have been ‘grandfathered’
from previous specifications.
Second, an entire language tag can consist of only a private use subtag. These tags
start with x-, and do not need to follow any further rules established by the IETF and endorsed
by these Guidelines. Like all language tags that make use of private use subtags,
the language in question must be documented in a corresponding <language> element in the TEI header.
Examples include
sn
Shona
zh-TW
Taiwanese
zh-Hant-HK
Chinese written in traditional script as used in Hong Kong
Attributes using this datatype must contain a single word which follows the rules
defining a legal XML name (see https://www.w3.org/TR/REC-xml/#dt-name): for example they cannot include whitespace or begin with digits.
Appendix A.5.7 teidata.numeric
teidata.numericdefines the range of attribute values used for numeric values.
Any numeric value, represented as a decimal number, in floating point format, or as
a ratio.
To represent a floating point number, expressed in scientific notation, ‘E notation’,
a variant of ‘exponential notation’, may be used. In this format, the value is expressed
as two numbers separated by the letter E. The first number, the significand (sometimes
called the mantissa) is given in decimal format, while the second is an integer. The
value is obtained by multiplying the mantissa by 10 the number of times indicated
by the integer. Thus the value represented in decimal notation as 1000.0 might be
represented in scientific notation as 10E3.
A value expressed as a ratio is represented by two integer values separated by a solidus
(/) character. Thus, the value represented in decimal notation as 0.5 might be represented
as a ratio by the string 1/2.
Appendix A.5.8 teidata.outputMeasurement
teidata.outputMeasurementdefines a range of values for use in specifying the size of an object that is intended
for display.
<figure><head>The TEI Logo</head><figDesc>Stylized yellow angle brackets with the letters <mentioned>TEI</mentioned> in
between and <mentioned>text encoding initiative</mentioned> underneath, all on a white
background.</figDesc><graphic height="600px" width="600px"
url="http://www.tei-c.org/logos/TEI-600.jpg"/></figure>
Note
These values map directly onto the values used by XSL-FO and CSS. For definitions
of the units see those specifications; at the time of this writing the most complete
list is in the CSS3 working draft.
Appendix A.5.9 teidata.pattern
teidata.patterndefines attribute values which are expressed as a regular expression.
A regular expression, often called a pattern, is an expression that describes a set of strings. They are usually used to give
a concise description of a set, without having to list all elements. For example,
the set containing the three strings Handel, Händel, and Haendel can be described by the pattern H(ä|ae?)ndel (or alternatively, it is said that the pattern H(ä|ae?)ndelmatches each of the three strings)
This TEI datatype is mapped to the XSD token datatype, and may therefore contain any
string of characters. However, it is recommended that the value used conform to the
particular flavour of regular expression syntax supported by XSD Schema.
Appendix A.5.10 teidata.point
teidata.pointdefines the data type used to express a point in cartesian space.
A point is defined by two numeric values, which should be expressed as decimal numbers.
Neither number can end in a decimal point. E.g., both 0.0,84.2 and 0,84 are allowed, but 0.,84. is not.
Appendix A.5.11 teidata.pointer
teidata.pointerdefines the range of attribute values used to provide a single URI, absolute or relative,
pointing to some other resource, either within the current document or elsewhere.
The range of syntactically valid values is defined by RFC 3986Uniform Resource Identifier (URI): Generic Syntax. Note that the values themselves are encoded using RFC 3987Internationalized Resource Identifiers (IRIs) mapping to URIs. For example, https://secure.wikimedia.org/wikipedia/en/wiki/% is encoded as https://secure.wikimedia.org/wikipedia/en/wiki/%25 while http://موقع.وزارة-الاتصالات.مصر/ is encoded as http://xn--4gbrim.xn----rmckbbajlc6dj7bxne2c.xn--wgbh1c/
Appendix A.5.12 teidata.prefix
teidata.prefixdefines a range of values that may function as a URI scheme name.
This datatype is used to constrain a string of characters to one that can be used
as a URI scheme name according to RFC 3986, section 3.1. Thus only the 26 lowercase letters a–z, the 10 digits 0–9, the plus sign, the period,
and the hyphen are permitted, and the value must start with a letter.
Appendix A.5.13 teidata.probCert
teidata.probCertdefines a range of attribute values which can be expressed either as a numeric probability
or as a coded certainty value.
Values for attributes using this datatype may be defined locally by a project, or
they may refer to an external standard.
Appendix A.5.17 teidata.temporal.w3c
teidata.temporal.w3cdefines the range of attribute values expressing a temporal expression such as a date,
a time, or a combination of them, that conform to the W3C XML Schema Part 2: Datatypes Second Edition specification.
If it is likely that the value used is to be compared with another, then a time zone
indicator should always be included, and only the dateTime representation should be
used.
Appendix A.5.18 teidata.text
teidata.textdefines the range of attribute values used to express some kind of identifying string
as a single sequence of Unicode characters possibly including whitespace.
The possible values of this datatype are 1 or true, or 0 or false.
This datatype applies only for cases where uncertainty is inappropriate; if the attribute
concerned may have a value other than true or false, e.g. unknown, or inapplicable, it should have the extended version of this datatype: teidata.xTruthValue.
Appendix A.5.20 teidata.unboundedCount
teidata.unboundedCountdefines the range of values used for a counting number or the string unbounded for infinity.
Attributes using this datatype must contain a single ‘word’ which contains only letters,
digits, punctuation characters, or symbols: thus it cannot include whitespace.
Appendix A.5.23 teidata.xpath
teidata.xpathdefines attribute values which contain an XPath expression.
Any XPath expression using the syntax defined in 6.2..
When writing programs that evaluate XPath expressions, programmers should be mindful
of the possibility of malicious code injection attacks. For further information about
XPath injection attacks, see the article at OWASP.
Appendix A.6 Constraints
Schematron
<sch:rule context="tei:person | tei:place | tei:list[@type='vessels']/tei:item">
<sch:assert test="matches(@xml:id, '^[a-z0-9_\-]+$')"> Only lower-case letters without
spaces should be used in @xml:id attributes
for people, places and vessels.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:listBibl/tei:bibl">
<sch:assert test="not(matches(., 'Ibid([^\.]|$)'))"> "Ibid" must be followed by a
period.
</sch:assert>
</sch:rule>
<sch:rule context="tei:listBibl/tei:bibl">
<sch:assert test="not(contains(., 'ibid'))"> "Ibid" should begin with a capital letter
and be followed by a period.
</sch:assert>
</sch:rule>
<sch:rule context="tei:listBibl[not(ancestor::tei:div[@type='schedule'])]/tei:bibl[not(@type)]">
<sch:assert test="matches(., '^\d+\.\s')"> Bibl entries must begin with a number,
followed by a period and a space.
</sch:assert>
</sch:rule>
<sch:rule context="tei:bibl/tei:hi[matches(., '\d+')]">
<sch:assert test="not(matches(following::text()[1], '^[\.;,:''"\?!\)]'))"> Superscripted
footnote numbers must appear after punctuation, not before.
</sch:assert>
</sch:rule>
<sch:rule context="tei:bibl[not(@type='book')][not(@type='journal_article')]/@xml:id">
<sch:assert test="matches(., concat(ancestor::tei:person/@xml:id, '_b_\d+'))"> The
convention for bibl xml:id = "xml:id here_b_number of endnote here".
</sch:assert>
</sch:rule>
<sch:rule context="tei:bibl[@corresp]">
<sch:let name="xID"
value="substring-after(@corresp, '#')"/>
<sch:assert test="ancestor::tei:TEI/descendant::tei:bibl[@xml:id=$xID]"> bibl @corresp
must match corresponding bibl @xml:id in footnotes.
</sch:assert>
</sch:rule>
<sch:rule context="tei:bibl[@corresp]/tei:hi">
<sch:assert test="matches(., '^\d+$')"> bibl indicator must be an integer with no
preceding or trailing spaces.
</sch:assert>
</sch:rule>
<sch:rule context="tei:listBibl/tei:bibl[@xml:id][not(@type='book')][not(@type='journal_article')]">
<sch:let name="biblNum"
value="tokenize(@xml:id, '_')[last()]"/>
<sch:let name="textNum"
value="tokenize(., '\.')[1]"/>
<sch:assert test="$biblNum[. = $textNum]"> number of @xml:id must match the number
of the citation.
</sch:assert>
</sch:rule>
<sch:rule context="tei:bibl[@corresp]">
<sch:assert test="not(preceding-sibling::node()[1][matches(., '\s$')])"> bibl indicator
must immediately follow a period or a closing q tag.
</sch:assert>
</sch:rule>
<sch:rule context="tei:title[@level=('a', 'm', 'j', 'u')]">
<sch:assert test="following-sibling::node()[1][matches(., '^[^\w\d]')] or ancestor::tei:item
or not(following-sibling::node())"> title elements should not be immediately followed
by alphanumeric characters.
You need a space or a punctuation mark followed by a space.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:*[@style] | tei:rendition[not(tei:label or tei:code)] | tei:rendition/tei:code">
<sch:let name="css"
value="if (./@style) then ./@style else ./text()"/>
<sch:assert test="matches($css, '^(((align-content)|(align-items)|(align-self)|(background-color)|(border)|(border-bottom)|(border-bottom-color)|(border-bottom-left-radius)|(border-bottom-right-radius)|(border-bottom-style)|(border-bottom-width)|(border-collapse)|(border-color)|(border-left)|(border-left-color)|(border-left-style)|(border-left-width)|(border-radius)|(border-right)|(border-right-color)|(border-right-style)|(border-right-width)|(border-spacing)|(border-style)|(border-top)|(border-top-color)|(border-top-left-radius)|(border-top-right-radius)|(border-top-style)|(border-top-width)|(border-width)|(bottom)|(box-decoration-break)|(box-shadow)|(box-sizing)|(caption-side)|(caret-color)|(@charset)|(clear)|(clip)|(color)|(content)|(counter-increment)|(counter-reset)|(display)|(float)|(font)|(@font-face)|(font-family)|(font-kerning)|(font-size)|(font-size-adjust)|(font-stretch)|(font-style)|(font-variant)|(font-weight)|(hanging-punctuation)|(height)|(hyphens)|(left)|(letter-spacing)|(line-height)|(list-style)|(list-style-image)|(list-style-position)|(list-style-type)|(margin)|(margin-bottom)|(margin-left)|(margin-right)|(margin-top)|(mix-blend-mode)|(opacity)|(outline)|(outline-color)|(outline-offset)|(outline-style)|(outline-width)|(overflow)|(overflow-x)|(overflow-y)|(padding)|(padding-bottom)|(padding-left)|(padding-right)|(padding-top)|(position)|(quotes)|(resize)|(right)|(table-layout)|(text-align)|(text-align-last)|(text-decoration)|(text-decoration-color)|(text-decoration-line)|(text-decoration-style)|(text-indent)|(text-justify)|(text-overflow)|(text-shadow)|(text-transform)|(top)|(transform)|(transform-origin)|(transform-style)|(unicode-bidi)|()|(vertical-align)|(visibility)|(white-space)|(width)|(word-break)|(word-spacing)|(word-wrap)|(writing-mode)|(z-index)):
[%#a-zA-Z\-\d\. ]+;(\s|$))+')"> This does not seem to be a valid CSS property name.
</sch:assert>
<sch:assert test="not(matches($css, 'strikethrough'))"> Sydney, "strikethrough" is
not a valid CSS value. The correct form is text-decoration: line-through.
</sch:assert>
<sch:assert test="not(matches($css, 'text-decoration\s*:\s*((bold)|(italic))'))">
Sydney, this is not correct CSS. You probably need either: font-weight: bold; or font-style:
italic;
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:name | tei:forename | tei:surname | tei:roleName | tei:title">
<sch:assert test="not(matches(., '^\s')) and not(matches(., '\s$'))"> Do not include
spaces at the beginning or end of name or title elements.
</sch:assert>
</sch:rule>
<sch:rule context="tei:name | tei:forename | tei:surname | tei:roleName">
<sch:assert test="not(matches(., '(''s$)|(s''$)|(’s$)|(s’$)')) or matches(., '(couver''s$)|(harlotte''s$)|(ra[sz]er''s$)')">
Do not include the possessive suffix inside a name tag.
</sch:assert>
</sch:rule>
<sch:rule context="tei:name | tei:forename | tei:surname | tei:roleName | tei:listBibl/tei:bibl
| tei:title | tei:ref[not(starts-with(@target, '#marg'))][not( @type='appURI')]">
<sch:assert test="not(matches(., '(''s$)|(s''$)|(’s$)|(s’$)')) or matches(., '(couver''s$)|(harlotte''s$)|(ra[sz]er''s$)')">
Do not include the possessive suffix inside a name tag.
</sch:assert>
</sch:rule>
<sch:rule context="tei:name | tei:forename | tei:surname | tei:roleName | tei:ref">
<sch:assert test="not(matches(., '[,;\?!]$'))"> Do not include trailing punctuation
inside a name or ref tag.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:seg[@type='snippet']">
<sch:assert test="not(child::tei:lb or child::tei:ref[starts-with(@target, '#marg')])">
Snippets may not contain elements which turn into blocks in the HTML output.
Keep your snippets as simple and short as possible, and avoid content which
has page-breaks, marginalia or other problematic blocks.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:*[@rend]">
<sch:assert test="not(contains(@rend, ':'))"> @rend should not be used for CSS code.
Please use the @style attribute
for CSS.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:q">
<sch:assert test="not(matches(., '(^\s)|(\s$)'))"> ERROR: No spaces are allowed at
the beginning or end of a q element.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:q">
<sch:let name="smartDouble" value="'[“”]'"/>
<sch:let name="straightDouble" value="'"'"/>
<sch:assert role="error"
test="not(matches(., $smartDouble))">No double quotes inside a q tag.</sch:assert>
<sch:assert role="error"
test="not(matches(., $straightDouble))">No double quotes inside a q tag.</sch:assert>
</sch:rule>
<sch:rule context="tei:note/tei:p/text()">
<sch:let name="smartDouble" value="'[“”]'"/>
<sch:let name="straightDouble" value="'"'"/>
<sch:assert role="error"
test="not(matches(., $smartDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
<sch:assert role="error"
test="not(matches(., $straightDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
</sch:rule>
<sch:rule context="tei:place/tei:desc/text()">
<sch:let name="smartDouble" value="'[“”]'"/>
<sch:let name="straightDouble" value="'"'"/>
<sch:assert role="error"
test="not(matches(., $smartDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
<sch:assert role="error"
test="not(matches(., $straightDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
</sch:rule>
<sch:rule context="tei:list[@type='vessels']/tei:item/tei:p/text()">
<sch:let name="smartDouble" value="'[“”]'"/>
<sch:let name="straightDouble" value="'"'"/>
<sch:assert role="error"
test="not(matches(., $smartDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
<sch:assert role="error"
test="not(matches(., $straightDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
</sch:rule>
<sch:rule context="tei:abstract/tei:p/text()">
<sch:let name="smartDouble" value="'[“”]'"/>
<sch:let name="straightDouble" value="'"'"/>
<sch:assert role="error"
test="not(matches(., $smartDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
<sch:assert role="error"
test="not(matches(., $straightDouble))">No double quotes. Please use <q> and <soCalled>
instead.</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:pb[@facs] | tei:biblScope[@facs]">
<sch:assert test="matches(@facs, '((co_\d+)|(rg7_g8c))_\d+_\d\d\d\d\d[a-z]*((-|_)\d+[rv]?)?($|(\.jpg))')
and not(matches(@facs, '00000'))"> This image link seems to be incorrect.
</sch:assert>
</sch:rule>
<sch:rule context="tei:div[@type='enclosures_transcribed']">
<sch:assert test="tei:div[@type='enclosure_transcribed']"> div with @type='enclosures_transcribed'
must have at least one div with @type='enclosure_transcribed'.
</sch:assert>
</sch:rule>
Schematron
<sch:rule context="tei:name[@type='vessel']">
<sch:assert test="not(matches(., '^(HMS|RMS|USS)'))"> Vessel prefixes, "HMS", "RMS",
"USS", must come before the name tag.
</sch:assert>
</sch:rule>
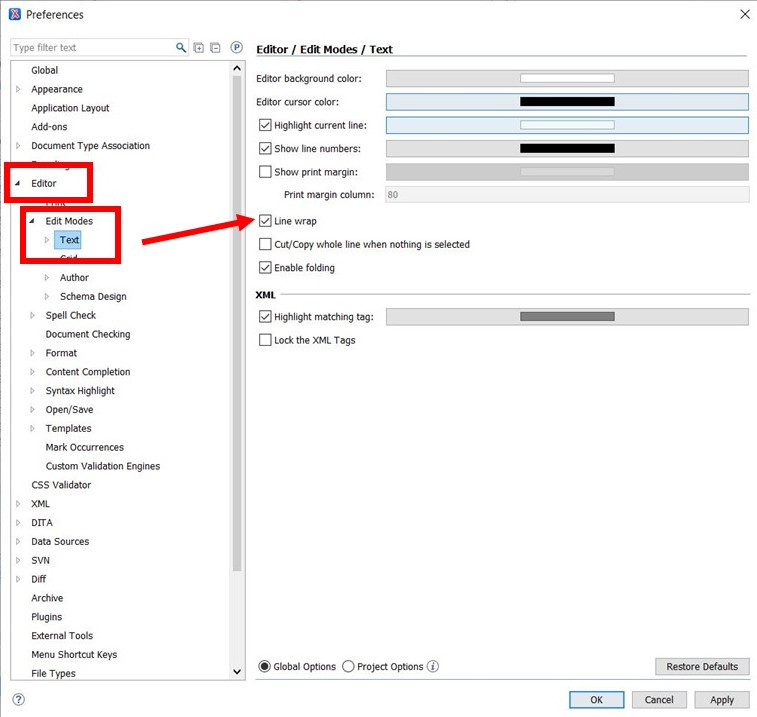
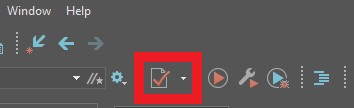
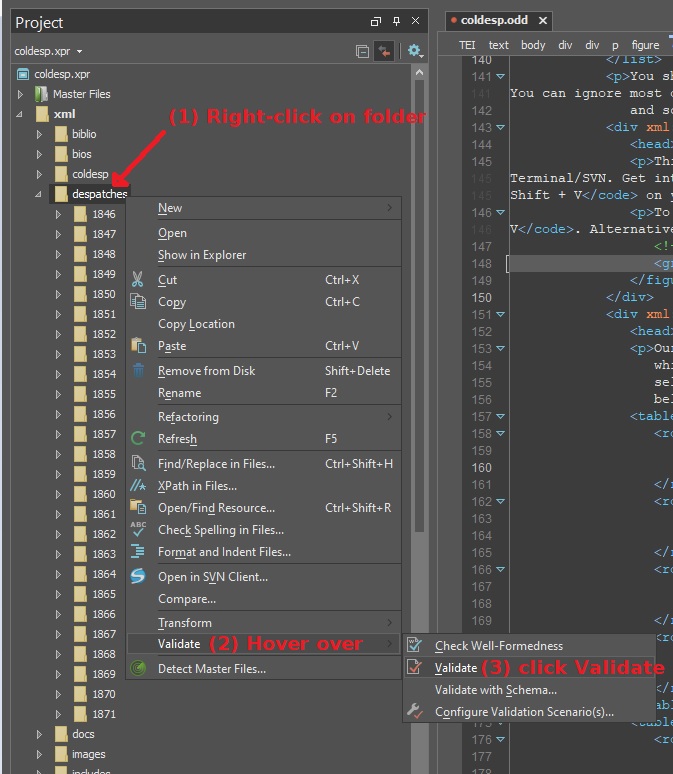


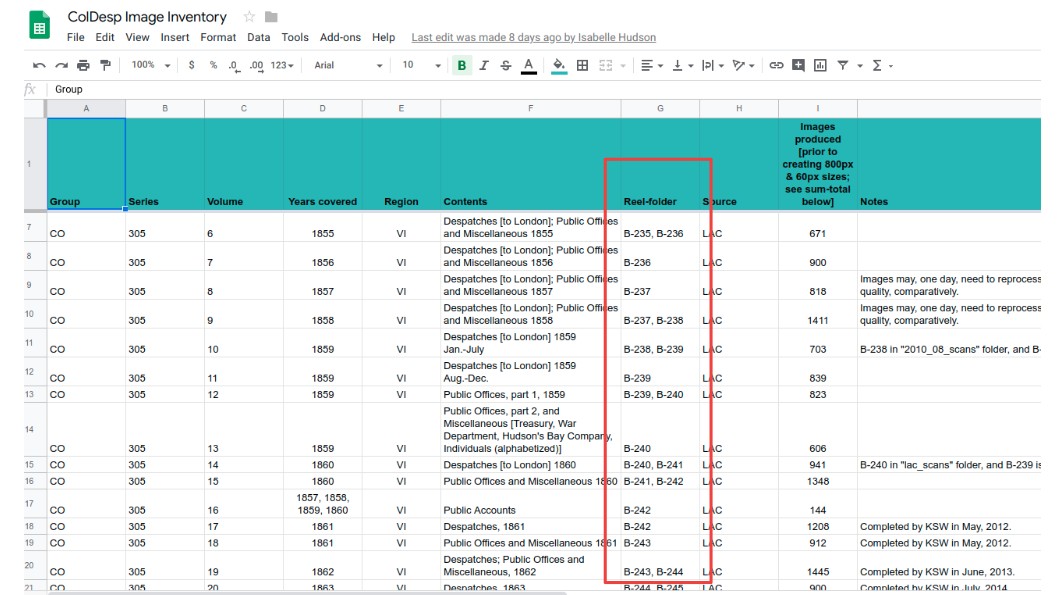
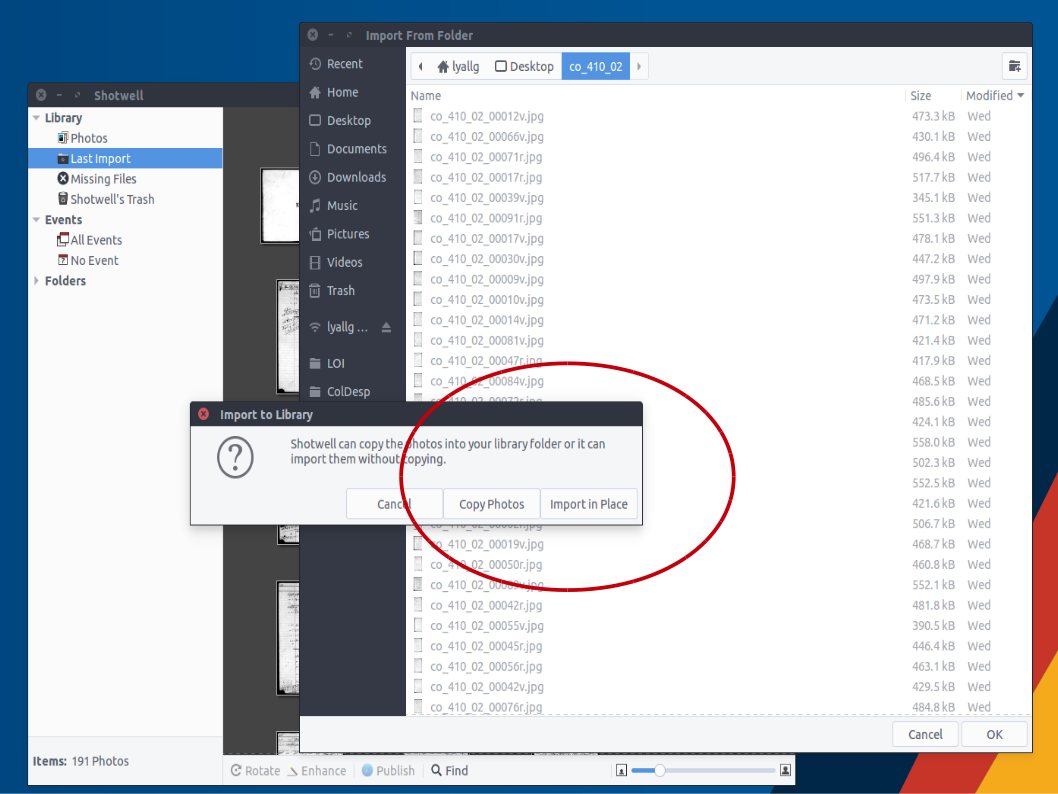
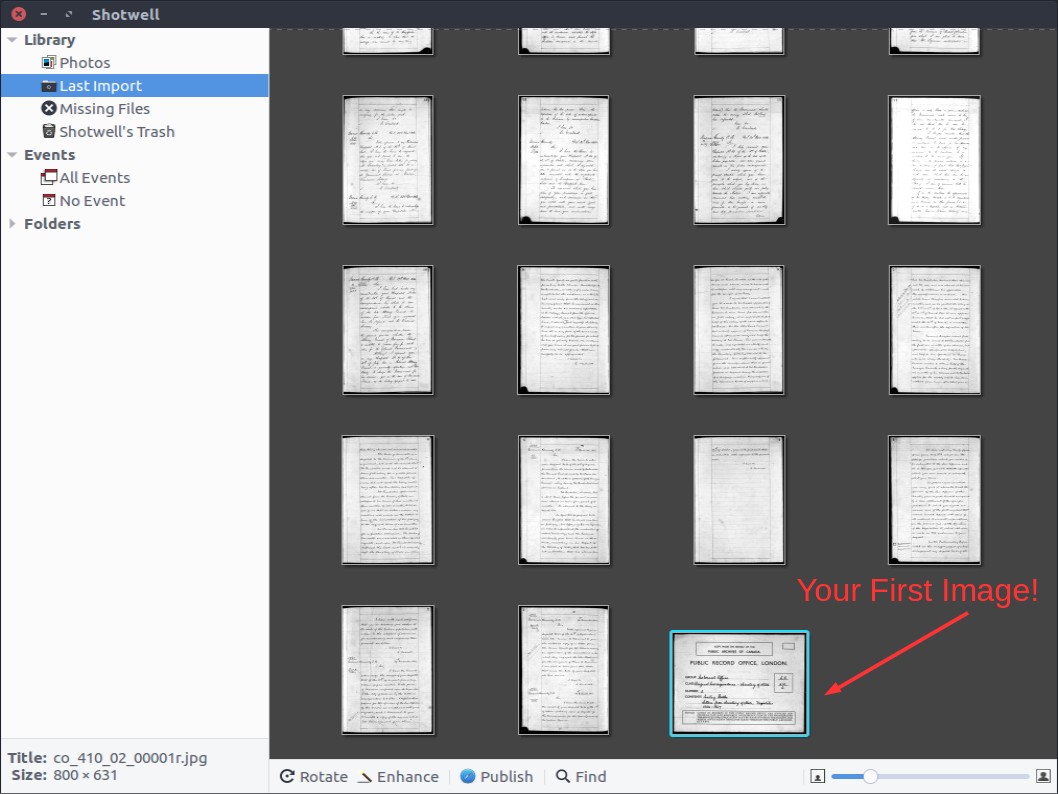
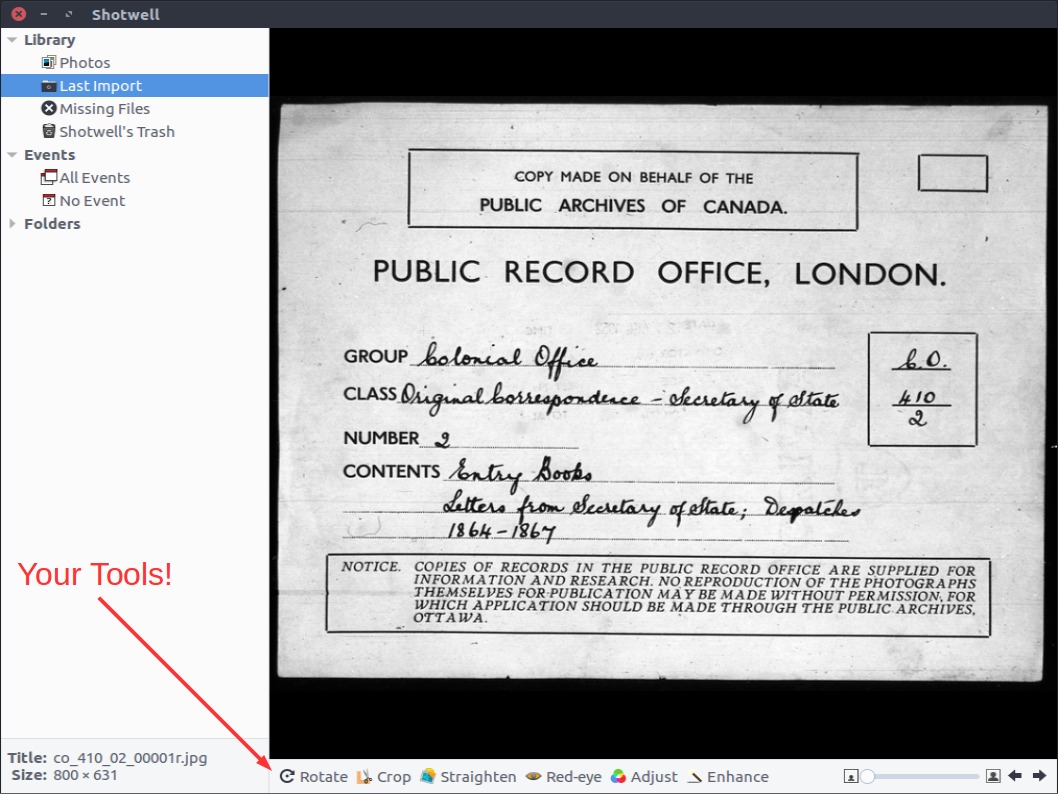




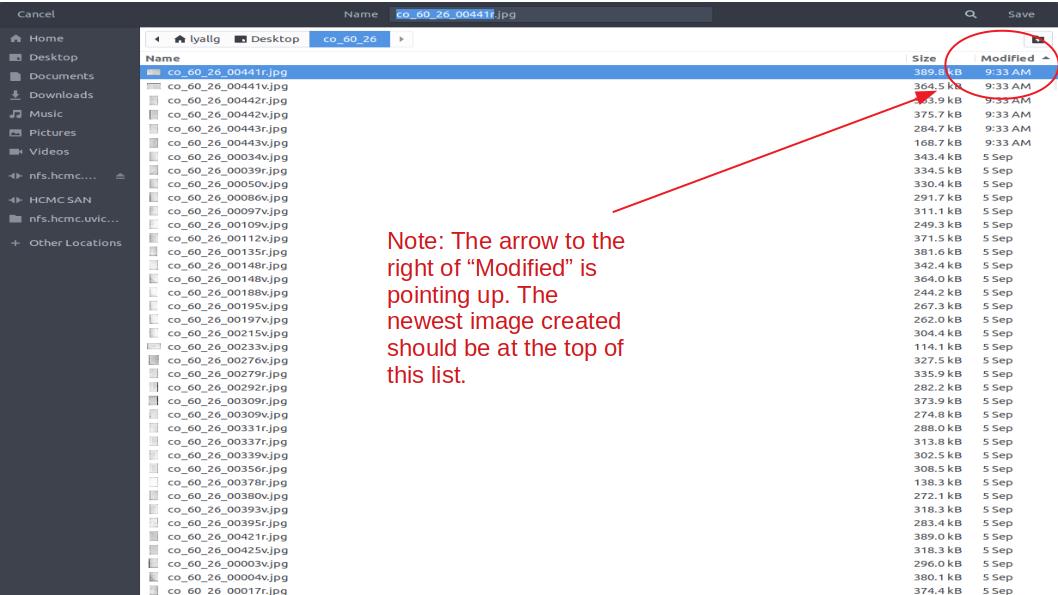




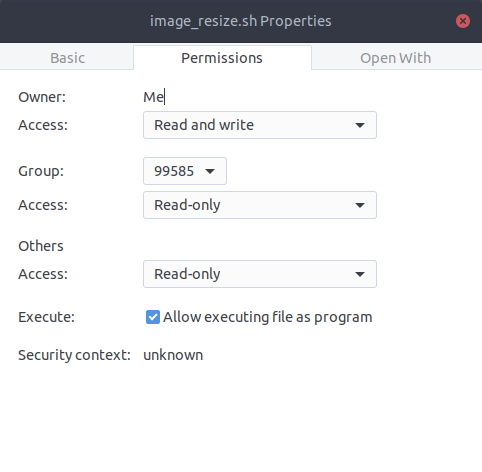







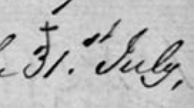



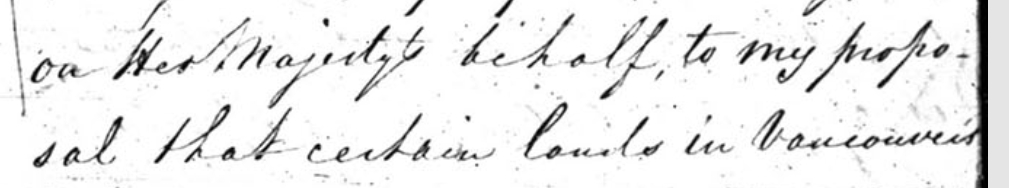




 <ref target="cdc:B58001#B00101">12719, CO 60/1, <name key="douglas_j">Douglas</name> to Lytton</ref>.
<ref target="cdc:B58001#B00101">12719, CO 60/1, <name key="douglas_j">Douglas</name> to Lytton</ref>.










 Finding Joseph Cahill
Finding Joseph Cahill <birth> and <death> elements commented out.
<birth> and <death> elements commented out. <birth> and <death> elements have been uncommented with dates filled in.
<birth> and <death> elements have been uncommented with dates filled in. Content added to bio
Content added to bio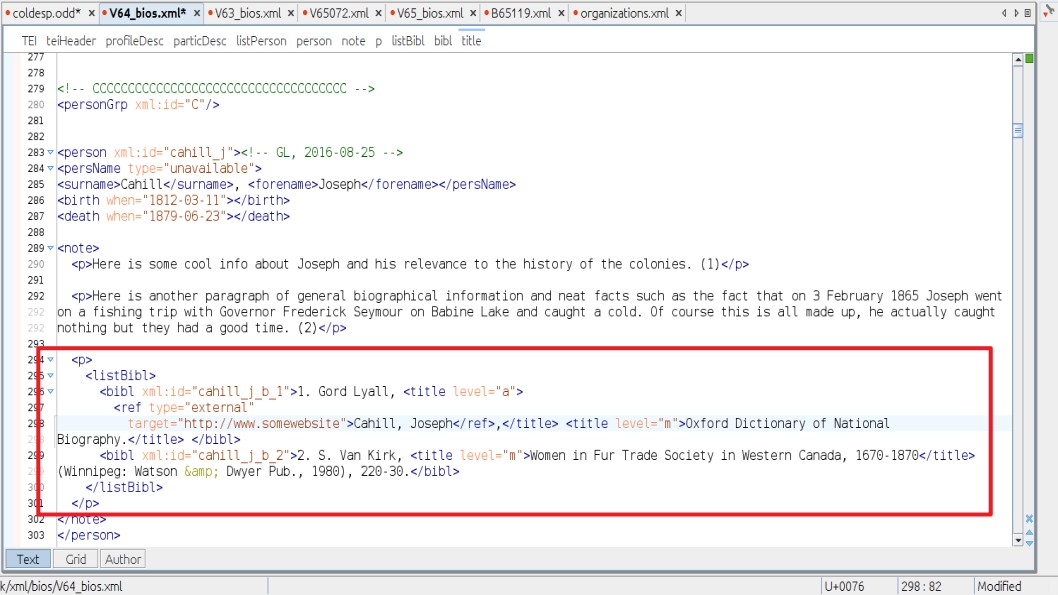 Added endnotes with xml:id. Examples are of an online dictionary and a book citation.
Added endnotes with xml:id. Examples are of an online dictionary and a book citation.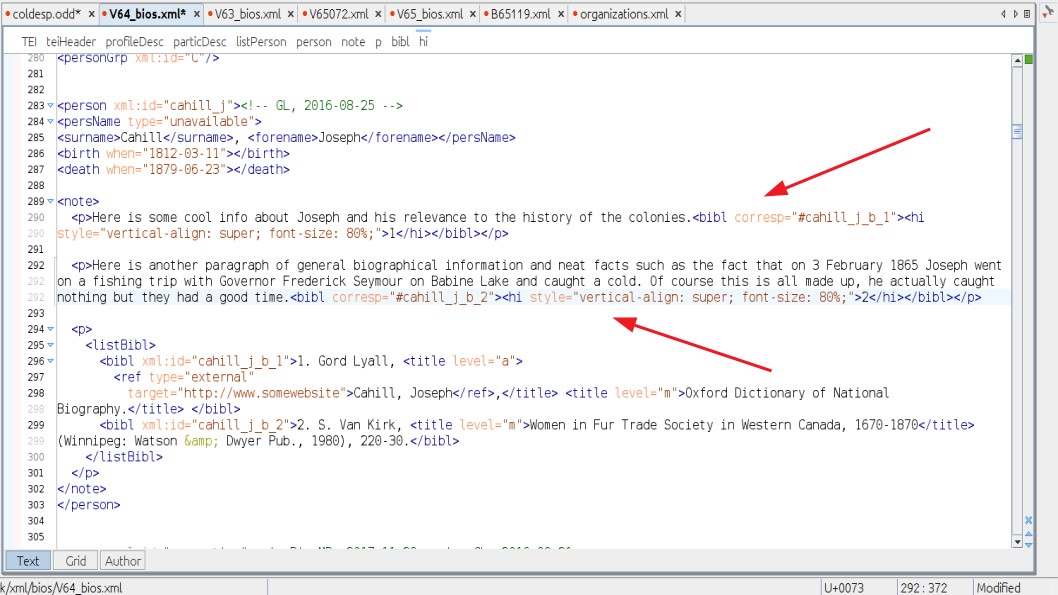 Indicators with full mark-up including corresp linking to the endnote.
Indicators with full mark-up including corresp linking to the endnote. Marked-up bio.
Marked-up bio. Pointing to type="unavailable.
Pointing to type="unavailable. type="unavailable is erased and writing credit comment added.
type="unavailable is erased and writing credit comment added.